
CNN을 활용한 주요 Model - (1) : Modern CNN
27 Jun 2018 | CNN
CNN을 활용한 주요 Model - (1) : Modern CNN
CNN을 활용한 최초의 기본적인 Model들 부터 계속해서 다양한 구조를 가지는 많은 모델들이 계속해서 나오고 있다. 이번 포스트에서는 아래의 분류를 기준으로 CNN의 주요 모델들에 대해서 하나씩 알아 보도록 하겠다.
- Modern CNN
- LeNet
- AlexNet
- VGG Nets
- GoogLeNet
- ResNet
- Image Detection
- RCNN
- Fast RCNN
- Faster RCNN
- SPP Net
- Yolo
- SDD
- Attention Net
- Semantic Segmentation
- FCN
- DeepLab v1, v2
- U-Net
- ReSeg
- Image Captioning
- LeNet
지난 포스트에서 얘기한 것 처럼 CNN 모델을 최초로 개발한 사람은 프랑스 출신의 Yann LeCun이며, 1989년 “Backpropagation applied to handwritten zip code recognition” 논문을 통해 최초로 CNN을 사용하였고, 이후 1998년 LeNet이라는 Network를 소개하였다.
LeNet은 우편번호와 수표의 필기체를 인식하기 위해 개발되었다. LeNet의 최종 모델인 LeNet5의 Architecture를 보면 아래와 같이 이루어져

LeNet 5는 총 7개의 Layer로 구성되어 있다. 두개의 Convolution Layer, 2개의 Sub-Sampling Layer, 2개의 Fully-Connected Layer 그리고 최종 출력 Layer로 이루어져 있다.
LeNet에 대한 자세한 내용은 LeNet Post를 참고하면 된다.
- AlexNet
보통 CNN을 얘기할 때 가장 먼저 얘기되는 AlexNet은 2012년 저명한 Computer Vision 대회인 ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)에서 2등(26.2%)보다 월등히 앞서 1등(15.4%)을 하며 소개되었다.
이렇게 월등히 높은 top-5 error로 세상은 CNN에 대해 주목을 하게 된 계기가 되었다.
AlexNet의 Architecture는 아래와 같다.
 구성은
구성은
- 5 Conv layer
- max polling layer
- drop out layer
- 3 FC layer
으로 이루어졌으며 병렬 구조를 이루고 있다.
AlexNet의 주요 포인트는 아래와 같다.
- 22000이상의 Categories를 가지는 1500만개 이상의 ImageNet data를 사용하였다.
- 비선형 함수인 ReLU를 사용하였다.(기존의 tanh함수를 사용할때 보다 ReLu를 사용하면서 학습시간이 줄었다)
- Data Augmentation 기술을 사용하였다(Image translation/Horizontal reflections/Patch extraction)
- 모델 최적화시 SGD를 사용하였고 가중지 감소와 모멘텀 기술을 사용했다.
- GTX 580을 사용해 5~6일 동안 학습하였다.
- VGG Net
AlexNet이후의 모델들에게 있어 가장 중요한 쟁점은 얼마나 더 Deep하게 모델을 만드는가 였다. 그런 Deep한 대표적인 모델이 VGG Net과 GoogLeNet이다.
VGG의 특징은 간단한 구조로 사용하기 쉽다는 점이다. 모든 Conv layer는 3x3filter를 동일하게 사용하고 1stride, 1pad를 사용한다. Sub-Sampling은 2x2 Max Polling을 2stride로 이뤄진다. 구조를 그림으로 보자.
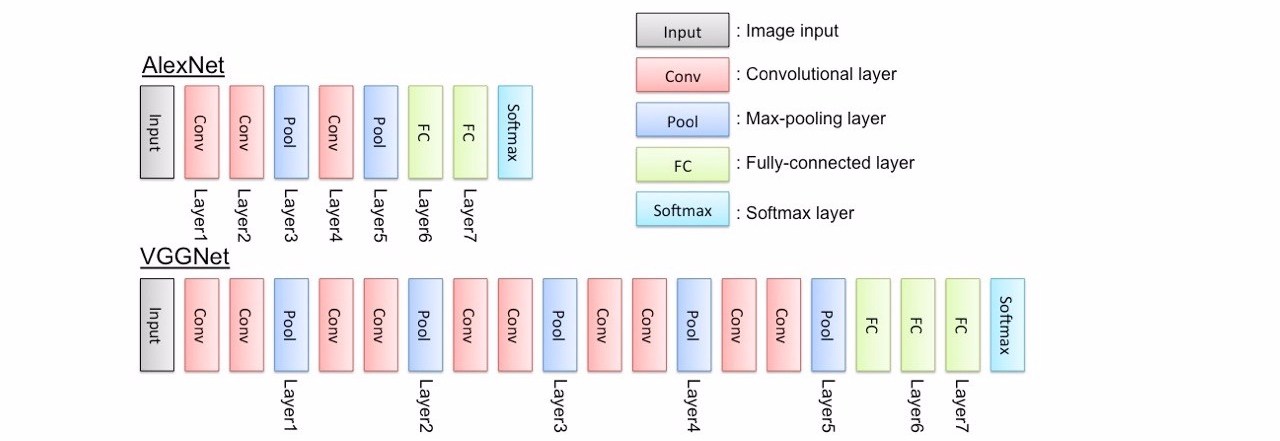
VGG Net의 주요포인트는 다음과 같다
- AlexNet의 11x11 filter와 ZFNet의 7x7 filter를 사용한 것과는 달리 VGG Net은 3x3 filter를 사용하였다. 뿐만 아니라 3x3 filter를 Convolution하는 layer를 두개씩 연이어 사용했다. 3x3 filter를 두번 사용함으로써 5x5 filter receptive field를 얻는것과 같은 효과를 얻는다.
- 3개의 연이은 conv layer를 통해 7x7 receptive field를 갖는 효과를 얻는다.
- max-pooling layer에서 input volume을 줄임으로써 network를 깊게 만든다.
- VGG Net을 통해 Image Classification과 Localization Task 둘다에 사용하였다.(Localization은 마지막 단에서 Regression을 사용하였다. Paper참고)
- Data Augmentation을 위해 scale jittering를 사용하였다.
- 각 conv layer이후 ReLU함수를 사용하였고, batch gradient descent를 사용했다.
- NVidia Titan Black GPU 4개를 사용해 2~3주간 학습했다.
- GoogLeNet
2014년 ILSVRC에서 Google은 GoogLeNet으로 VGG를 재치고 근소한 차이로 1등을 차지하게 된다.
이때부터의 모델들이 주목하던 부분은 얼마나 깊게(Deep) 모델을 만드는 것이다. 기존의 filter를 여러개 사용하던 LeNet, AlexNet과는 달리 하나의 Conv Layer에서 1개의 filter만 사용되었다.
우선 기본 architecture부터 살펴보면 이전의 model들 보다는 훨씬 더 깊다는 것을 한눈에 알 수 있다.
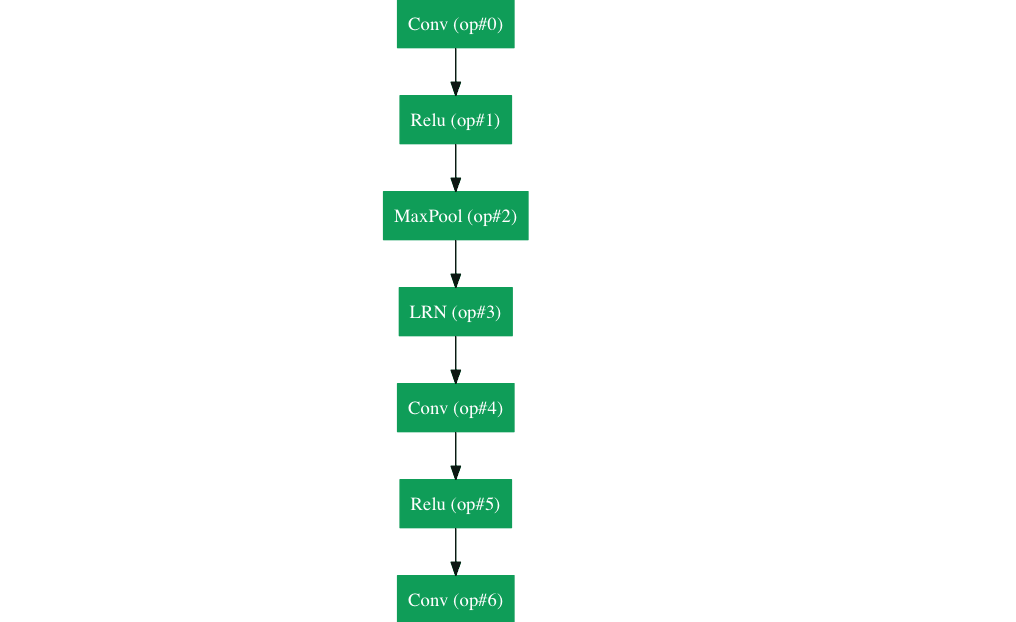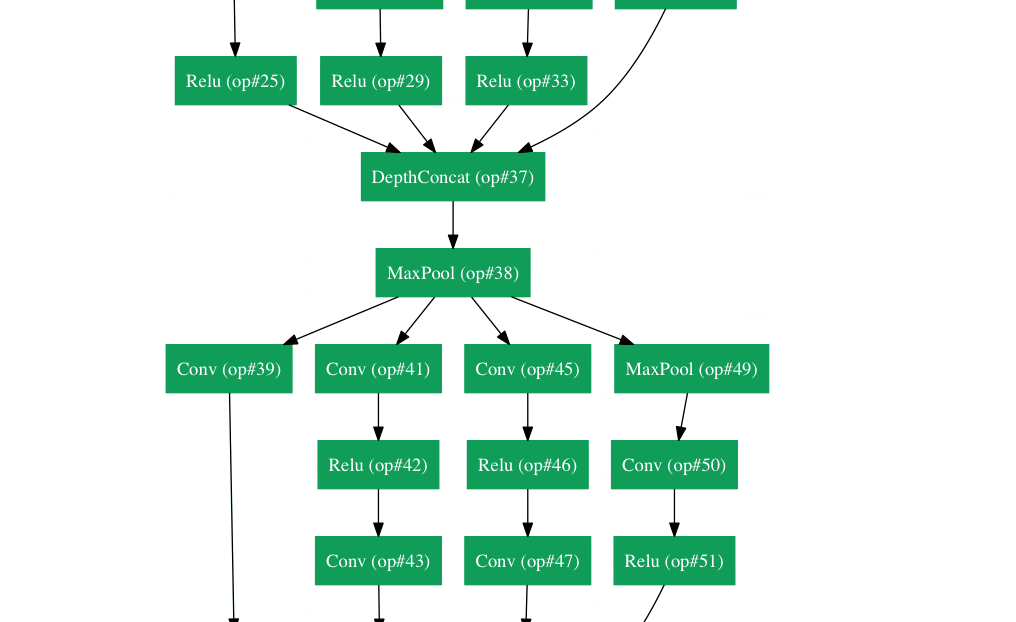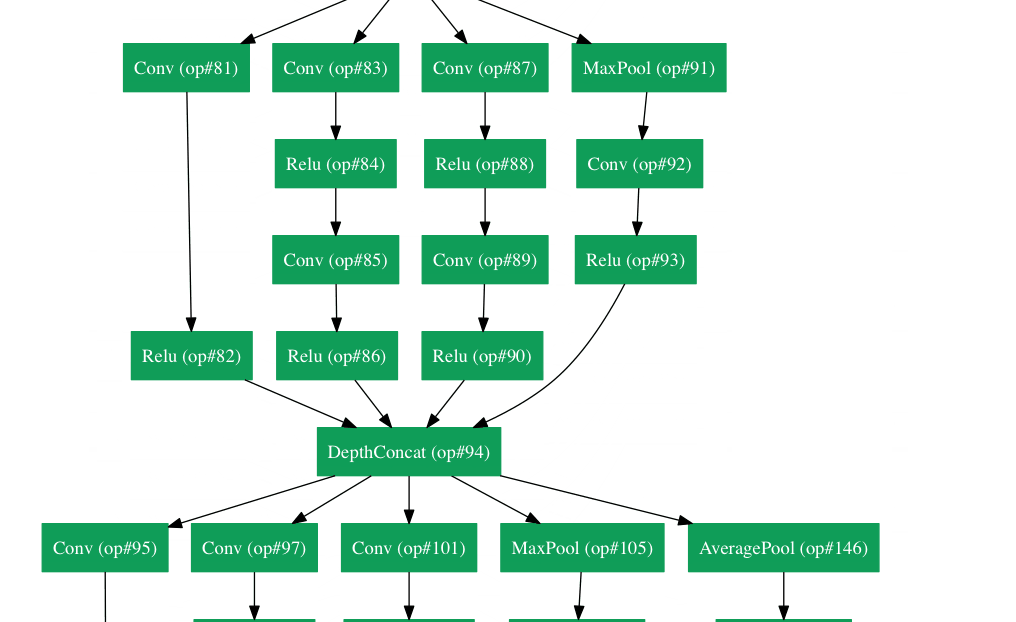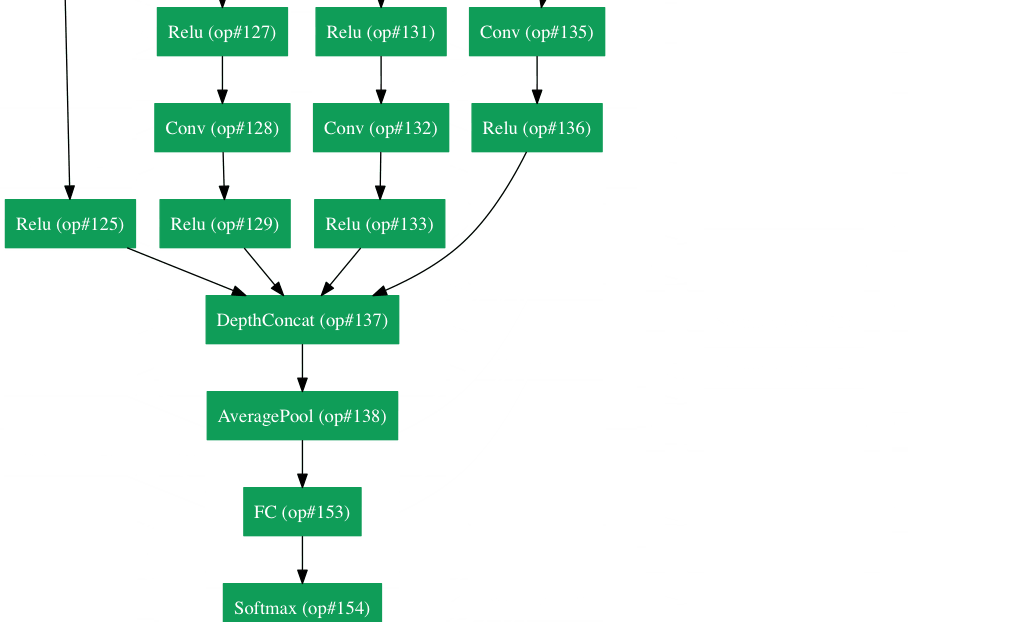
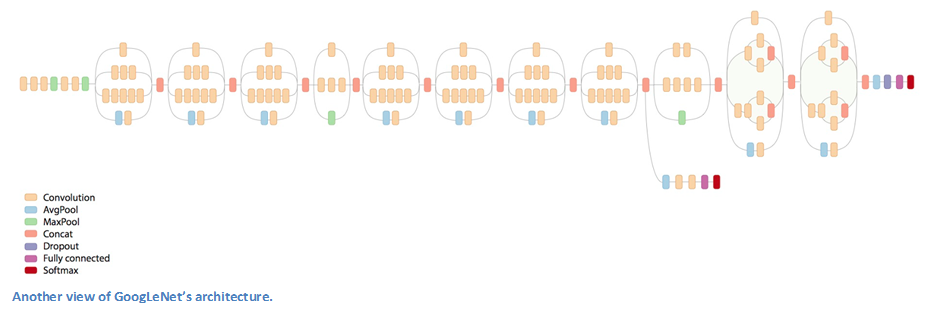 총 22개의
총 22개의
GoogLeNet에서 사용된 가장 중요한 기술은 Inception-module 을 사용했다는 점이다.
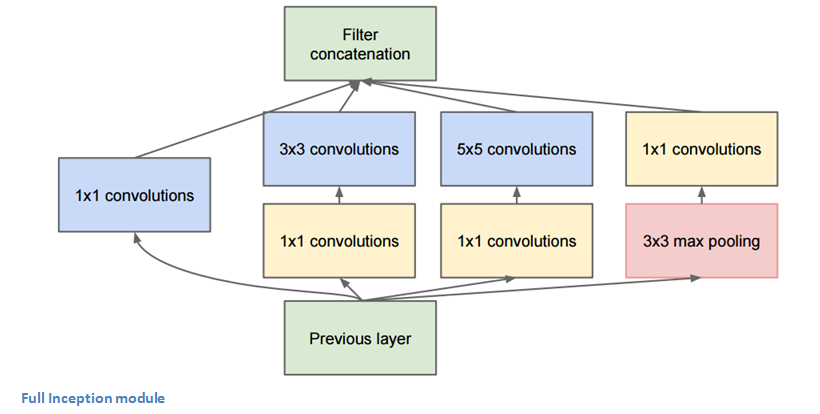 Inception module을 사용함으로써 Parameter 수를 획기적으로 줄였으며, 다양한 receptive field를 가지는 convolution들을 concatenate함으로써 이미지 인식률을 높였다.
Inception module을 사용함으로써 Parameter 수를 획기적으로 줄였으며, 다양한 receptive field를 가지는 convolution들을 concatenate함으로써 이미지 인식률을 높였다.
GoogLeNet의 주요 포인트은 아래와 같다.
- 9개의 Inception modules을 사용하면서 총 100개가 넘는 깊은 network를 가진다.
- FC layer를 사용하지않고 average pooling을 사용해 7x7x1024를 1x1x1024로 만들었다. 이과정을 통해 파라미터 수를 획기적으로 줄였다.
- R-CNN concept를 사용하였다(for detection model)
- Inception model은 계속해서 Update되었다(~7)
- 학습은 GPU를 활용해 한주동안 하였다.
- ResNet
이전까지의 AlexNet이후의 Model들은 모델들을 깊게 쌓음으로써 높은 인식률을 보여줬다. 하지만 깊게 쌓으면서 몇 가지 문제가 발생했다.
- Vanishing/Exploding Gradient : Parameter학습 시 gradient값이 너무 크거나 작아서 학습이 제대로 이뤄지지 않는 문제이다. 보통 Batch Normalization, parameter 초기값 설정 등으로 해결 하지만 layer가 깊어질 수록 해결이 어렵다.
- Degeneration : depth를 깊게 쌓으면서 일정 깊이 이상 넘어갈 시 성능이 더 좋아지지 않는 문제.
ResNet은 이러한 문제를 Residual Block을 통해 해결 하고 ILSVRC 2015에서 3.6%의 error 라는 놀라울 결과를 보여주었다.
Residual Block
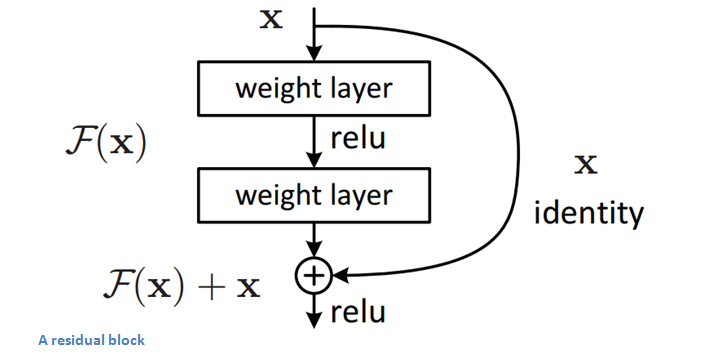 Residual Block은 input에 대해 layer를 통과시킨 값($F(x)$)을 바로 다음 단으로 통과시키는 것이 아니라 Input값을 더해서 다음 단으로 통과시킨다.($F(x)+x$)
이러한 구조를 통해 저자는 학습이 훨씬 쉬워졌다고 말한다. 또한 Back propagation과정에서 gradient값이 $x$를 더함으로써 더욱 이전 단으로 잘 전달된다.
Residual Block은 input에 대해 layer를 통과시킨 값($F(x)$)을 바로 다음 단으로 통과시키는 것이 아니라 Input값을 더해서 다음 단으로 통과시킨다.($F(x)+x$)
이러한 구조를 통해 저자는 학습이 훨씬 쉬워졌다고 말한다. 또한 Back propagation과정에서 gradient값이 $x$를 더함으로써 더욱 이전 단으로 잘 전달된다.
나머지 Model들에 대해서는 다음 포스트에서 계속해서 알아보도록 하겠다.
출처
CNN을 활용한 주요 Model - (1) : Modern CNN
CNN을 활용한 최초의 기본적인 Model들 부터 계속해서 다양한 구조를 가지는 많은 모델들이 계속해서 나오고 있다. 이번 포스트에서는 아래의 분류를 기준으로 CNN의 주요 모델들에 대해서 하나씩 알아 보도록 하겠다.
- Modern CNN
- LeNet
- AlexNet
- VGG Nets
- GoogLeNet
- ResNet
- Image Detection
- RCNN
- Fast RCNN
- Faster RCNN
- SPP Net
- Yolo
- SDD
- Attention Net
- Semantic Segmentation
- FCN
- DeepLab v1, v2
- U-Net
- ReSeg
- Image Captioning
- LeNet
지난 포스트에서 얘기한 것 처럼 CNN 모델을 최초로 개발한 사람은 프랑스 출신의 Yann LeCun이며, 1989년 “Backpropagation applied to handwritten zip code recognition” 논문을 통해 최초로 CNN을 사용하였고, 이후 1998년 LeNet이라는 Network를 소개하였다.
LeNet은 우편번호와 수표의 필기체를 인식하기 위해 개발되었다. LeNet의 최종 모델인 LeNet5의 Architecture를 보면 아래와 같이 이루어져
LeNet 5는 총 7개의 Layer로 구성되어 있다. 두개의 Convolution Layer, 2개의 Sub-Sampling Layer, 2개의 Fully-Connected Layer 그리고 최종 출력 Layer로 이루어져 있다.
LeNet에 대한 자세한 내용은 LeNet Post를 참고하면 된다.
- AlexNet
보통 CNN을 얘기할 때 가장 먼저 얘기되는 AlexNet은 2012년 저명한 Computer Vision 대회인 ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)에서 2등(26.2%)보다 월등히 앞서 1등(15.4%)을 하며 소개되었다. 이렇게 월등히 높은 top-5 error로 세상은 CNN에 대해 주목을 하게 된 계기가 되었다.
AlexNet의 Architecture는 아래와 같다.
구성은
- 5 Conv layer
- max polling layer
- drop out layer
- 3 FC layer
으로 이루어졌으며 병렬 구조를 이루고 있다.
AlexNet의 주요 포인트는 아래와 같다.
- 22000이상의 Categories를 가지는 1500만개 이상의 ImageNet data를 사용하였다.
- 비선형 함수인 ReLU를 사용하였다.(기존의 tanh함수를 사용할때 보다 ReLu를 사용하면서 학습시간이 줄었다)
- Data Augmentation 기술을 사용하였다(Image translation/Horizontal reflections/Patch extraction)
- 모델 최적화시 SGD를 사용하였고 가중지 감소와 모멘텀 기술을 사용했다.
- GTX 580을 사용해 5~6일 동안 학습하였다.
- VGG Net
AlexNet이후의 모델들에게 있어 가장 중요한 쟁점은 얼마나 더 Deep하게 모델을 만드는가 였다. 그런 Deep한 대표적인 모델이 VGG Net과 GoogLeNet이다.
VGG의 특징은 간단한 구조로 사용하기 쉽다는 점이다. 모든 Conv layer는 3x3filter를 동일하게 사용하고 1stride, 1pad를 사용한다. Sub-Sampling은 2x2 Max Polling을 2stride로 이뤄진다. 구조를 그림으로 보자.
VGG Net의 주요포인트는 다음과 같다
- AlexNet의 11x11 filter와 ZFNet의 7x7 filter를 사용한 것과는 달리 VGG Net은 3x3 filter를 사용하였다. 뿐만 아니라 3x3 filter를 Convolution하는 layer를 두개씩 연이어 사용했다. 3x3 filter를 두번 사용함으로써 5x5 filter receptive field를 얻는것과 같은 효과를 얻는다.
- 3개의 연이은 conv layer를 통해 7x7 receptive field를 갖는 효과를 얻는다.
- max-pooling layer에서 input volume을 줄임으로써 network를 깊게 만든다.
- VGG Net을 통해 Image Classification과 Localization Task 둘다에 사용하였다.(Localization은 마지막 단에서 Regression을 사용하였다. Paper참고)
- Data Augmentation을 위해 scale jittering를 사용하였다.
- 각 conv layer이후 ReLU함수를 사용하였고, batch gradient descent를 사용했다.
- NVidia Titan Black GPU 4개를 사용해 2~3주간 학습했다.
- GoogLeNet
2014년 ILSVRC에서 Google은 GoogLeNet으로 VGG를 재치고 근소한 차이로 1등을 차지하게 된다.
이때부터의 모델들이 주목하던 부분은 얼마나 깊게(Deep) 모델을 만드는 것이다. 기존의 filter를 여러개 사용하던 LeNet, AlexNet과는 달리 하나의 Conv Layer에서 1개의 filter만 사용되었다.
우선 기본 architecture부터 살펴보면 이전의 model들 보다는 훨씬 더 깊다는 것을 한눈에 알 수 있다.
총 22개의
GoogLeNet에서 사용된 가장 중요한 기술은 Inception-module 을 사용했다는 점이다.
Inception module을 사용함으로써 Parameter 수를 획기적으로 줄였으며, 다양한 receptive field를 가지는 convolution들을 concatenate함으로써 이미지 인식률을 높였다.
GoogLeNet의 주요 포인트은 아래와 같다.
- 9개의 Inception modules을 사용하면서 총 100개가 넘는 깊은 network를 가진다.
- FC layer를 사용하지않고 average pooling을 사용해 7x7x1024를 1x1x1024로 만들었다. 이과정을 통해 파라미터 수를 획기적으로 줄였다.
- R-CNN concept를 사용하였다(for detection model)
- Inception model은 계속해서 Update되었다(~7)
- 학습은 GPU를 활용해 한주동안 하였다.
- ResNet
이전까지의 AlexNet이후의 Model들은 모델들을 깊게 쌓음으로써 높은 인식률을 보여줬다. 하지만 깊게 쌓으면서 몇 가지 문제가 발생했다.
- Vanishing/Exploding Gradient : Parameter학습 시 gradient값이 너무 크거나 작아서 학습이 제대로 이뤄지지 않는 문제이다. 보통 Batch Normalization, parameter 초기값 설정 등으로 해결 하지만 layer가 깊어질 수록 해결이 어렵다.
- Degeneration : depth를 깊게 쌓으면서 일정 깊이 이상 넘어갈 시 성능이 더 좋아지지 않는 문제.
ResNet은 이러한 문제를 Residual Block을 통해 해결 하고 ILSVRC 2015에서 3.6%의 error 라는 놀라울 결과를 보여주었다.
Residual Block
Residual Block은 input에 대해 layer를 통과시킨 값($F(x)$)을 바로 다음 단으로 통과시키는 것이 아니라 Input값을 더해서 다음 단으로 통과시킨다.($F(x)+x$)
이러한 구조를 통해 저자는 학습이 훨씬 쉬워졌다고 말한다. 또한 Back propagation과정에서 gradient값이 $x$를 더함으로써 더욱 이전 단으로 잘 전달된다.
나머지 Model들에 대해서는 다음 포스트에서 계속해서 알아보도록 하겠다.
출처
Comments