
CNN을 활용한 주요 Model - (2) : Image Detection
27 Jun 2018 | CNN
CNN을 활용한 주요 Model - (2) : Image Detection
CNN을 활용한 최초의 기본적인 Model들 부터 계속해서 다양한 구조를 가지는 많은 모델들이 계속해서 나오고 있다. 이번 포스트에서는 아래의 분류를 기준으로 CNN의 주요 모델들에 대해서 하나씩 알아 보도록 하겠다.
- Modern CNN
- LeNet
- AlexNet
- VGG Nets
- GoogLeNet
- ResNet
- Image Detection
- RCNN
- Fast RCNN
- Faster RCNN
- SPP Net
- Yolo
- SDD
- Attention Net
- Semantic Segmentation
- FCN
- DeepLab v1, v2
- U-Net
- ReSeg
- Image Captioning
Computer vision분야에는 다양한 문제들이 있다. 우선 Computer Vision의 Task들에 대해서 먼저 알아보자.

- Classification이란, Object가 하나있는 image에 대해서 Object의 class를 분류하는 문제이다.
- Classification과 Localization을 합친 문제는 Object의 class 분류와 object의 위치는 bounding box로 위치를 찾는 문제다.
- Object Detection은 우선 Image에 있어 single object가 아닌 multiple object를 다루는 문제다. 각각의 Object에 대해 class를찾고 위치를 찾는 문제다.
- Image Segmentation이란 Object Detection과 유사하지만, 다른점은 Object의 위치를 bounding box를 통해 나타내는것이 아닌 Object의 실제 edge를 찾아 정확한 형체까지 찾아 내는 문제이다.
이번 포스트에서는 Image Detection에서 사용된 CNN 모델들에 대해서 보도록한다.
- RCNN, Fast RCNN, Faster RCNN
2013년의 RCNN의 등장이후 Fast RCNN, Faster RCNN 까지 RCNN모델들은 많은 사람들에게 영향을 주었으며, Computer Vision분야에서 가장 Impactful한 network라 할 수 있다.
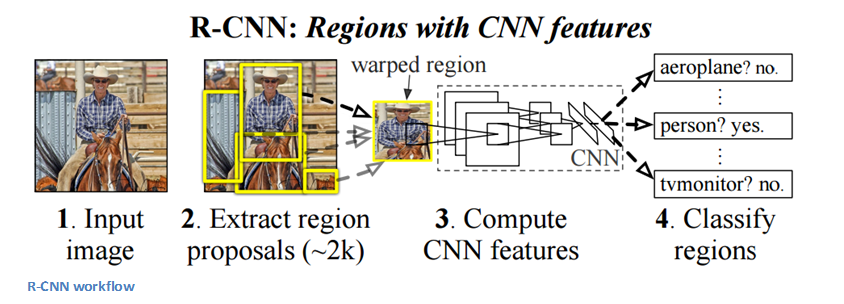
RCNN
RCNN의 목적은 Object Detection 문제를 풀기 위함이다. 어떠한 이미지가 주어지면, 그 이미지에 있는 모든 Object들에 대해 Bounding box를 그리는 것이 최종 목적이다. 따라서 문제는 두가지 과정으로 나뉜다. 첫 번째, Resion Proposal과정과 Classification과정으로 나뉜다.
RCNN은 Selective Search를 사용한다. Selective Search란 Image에 대해서 2000개 정도의 각각 다른 region을 생성해낸 후 물체가 들어가 있을 확률이 가장 높은 것을 뽑는 과정이다.
이렇게 Region을 뽑아내는 Region proposal 과정을 거친 후 bounding된 Image들에 대해 AlexNet을 통과시켜 Feature extraction 과정을 거친다.(Image들은 AlexNet에 넣기 위해 227x227크기로 reshape한다) 이때 AlexNet을 통과시켜 나오는 최종 Output값을 뽑는 것이 아니라, 최종 출력층 이전 두 번째 FC Layer의 output 값인 4,096크기의 vector를 뽑는 것이다. 4,096크기의 vector에 대해 linear SVM(각 class들에 대해 사전 학습 된)을 통해 각 Region을 Scoring한다. 마지막으로 각 region들에 대해 Non-Maximum Suppression(NMS)를 사용해 bounding box를 구한다.
다시한번 과정을 정리하면
- Selective Search Algorithms을 통해 2000개정도의 region을 생성한다.
- 각각의 region들을 228x228 크기로 Reshape한다.
- reshape한 image들을 AlexNet을 통과시켜 마지막 output이전의 FC Layer의 output인 4,096크기의 vector를 뽑아낸다.
- 뽑아낸 vector를 SVM을 통해 classification을 한다.
RCNN의 Process를 보다보면 생각보다 복잡하며, 과도한 연산 및 손실되는 정보가 많은 것 같다는 생각이 든다.
실제로 2000개 정도의 region에 대해 연산을 실행하면서 연산량이 늘어나며 image를 reshape하며 손실되는 정보들 또한 많다는 단점이 있다.
Fast-RCNN
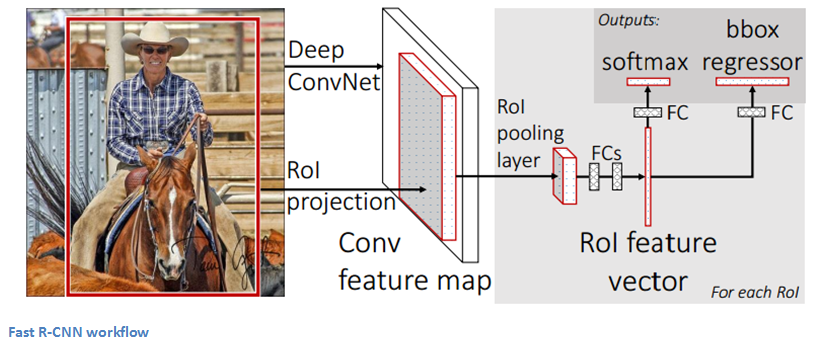 Fast-RCNN은 기존의 RCNN모델의 주요한 문제들을 해결하기 위해 나왔다.
Fast-RCNN은 기존의 RCNN모델의 주요한 문제들을 해결하기 위해 나왔다.
- RCNN은 학습을 위해 최소한 3가지 과정을 거쳐야한다.(CNN, SVM, region regression) 따라서 연산량이 매우 높아져서 속도가 매우느려 실제로 사용하기에 어렵다.
Fast RCNN의 과정을 설명하면
- Image를 ConvNet을 통과시켜 ConvNet의 마지막 Feature map을 region proposal의 feature로 얻는다.
- RoI Pooling layer를 통해 각각의 Bounding box에 대해 fixed-size의 feature vector를 얻는다.
- 마지막으로 feature vector에 대해 FC layer를 통해 class label과 bounding box location을 output으로 받는다.
여기서 처음에 통과시키는 ConvNet에서 Bounding box를 얻는 과정은 SPP Net의 방법과 유사하다. SPP Net에 대해서는 아래에서 보도록 하겠다.
Faster-RCNN
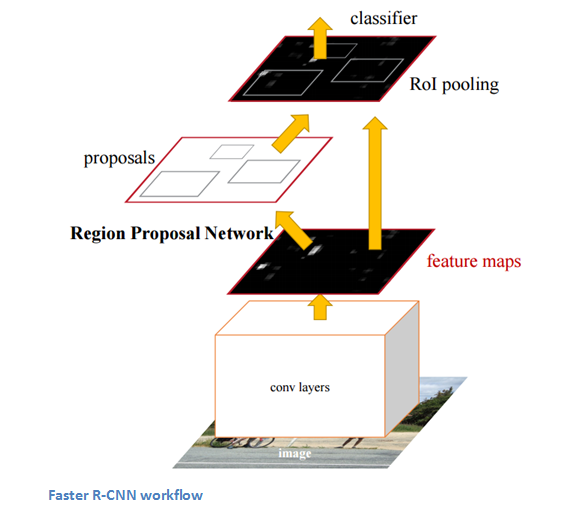 Faster RCNN은 RCNN과 Faster RCNN의 복잡한 학습과정 때문에 나오게 되었다. 여기서는 Region proposal network가 Convolution layer로 feature map을 뽑은 이후 나온다. Region Proposal Network외의 나머지 pipeline은 Fast-RCNN의 것과 똑같다.(ROI, FC, Classification, Regression)
Faster RCNN은 RCNN과 Faster RCNN의 복잡한 학습과정 때문에 나오게 되었다. 여기서는 Region proposal network가 Convolution layer로 feature map을 뽑은 이후 나온다. Region Proposal Network외의 나머지 pipeline은 Fast-RCNN의 것과 똑같다.(ROI, FC, Classification, Regression)
- SPP Net
SPP Net이란, Spatial Pyramid Pooling Network의 준말이다.
SPPNet은 RCNN이 나온 후 등장한 Network이다. RCNN에서는 region을 여러개 뽑은 후 CNN에 넣게 되는데, CNN에 Input값으로 넣기 위해서는 fixed-size의 image가 되어야한다. 이 과정에서 많은 정보들이 손실되는 문제점이 발생한다. 따라서 region을 만든후 Convlution layer를 통과시키는 것이 아니라, 먼저 Convolution layer를 통과시킨다. 이때 각각의 filter들은 다양한 size의 feature map들을 만든다. 이렇게 만들어진 다양한 size의 map에 대해서 feature extraction을 수행한다.

그다음 SPP Net에서 사용한 중요한 구조는 이름에서도 알 수 있듯이 Spatial Pyramid Pooling Layer이다. 이전의 다양한 size에서 Extracted feature들을 SPP Layer를 통과시킨 후 FC-layer를 통해 최종 Output값을 얻는다.
가장 중요한 SPP Layer에 대해서 살펴보자.
 SPP Layer에서는 Conv Layer에서 나온 feature map들에 대해서 다양한 사이즈로 pooling을 진행한다.(1x1, 2x2, 3x3 등) 다양한 크기로 Pooling을 한 뒤 이 값들을 하나의 vector로 만들어준다.
SPP Layer에서는 Conv Layer에서 나온 feature map들에 대해서 다양한 사이즈로 pooling을 진행한다.(1x1, 2x2, 3x3 등) 다양한 크기로 Pooling을 한 뒤 이 값들을 하나의 vector로 만들어준다.
이러한 과정을 통해 SPP Net은 RCNN에 비해 월등히 빠른 속도를 가지고 있다. 그럼에도 불구하고 학습이 어렵다는 단점과 여전히 Pipeline이 복잡하다는 단점이 존재한다.
- YOLO
YOLO란 우리가 흔히 You Only Look Once의 약자로 기존의 Object detection 알고리즘들의 속도가 real-time으로 사용하기에는 느리다는 문제점을 해결하기 위해 나온 알고리즘이다.
YOLO의 가장 큰 특징은 이름에서 나오듯이 Image를 bounding box를 찾을때와 classification을 따로하는 것이 아니라 두가지를 한번에 한다는 것이다.
YOLO의 실행 과정에 대해 소개하면,
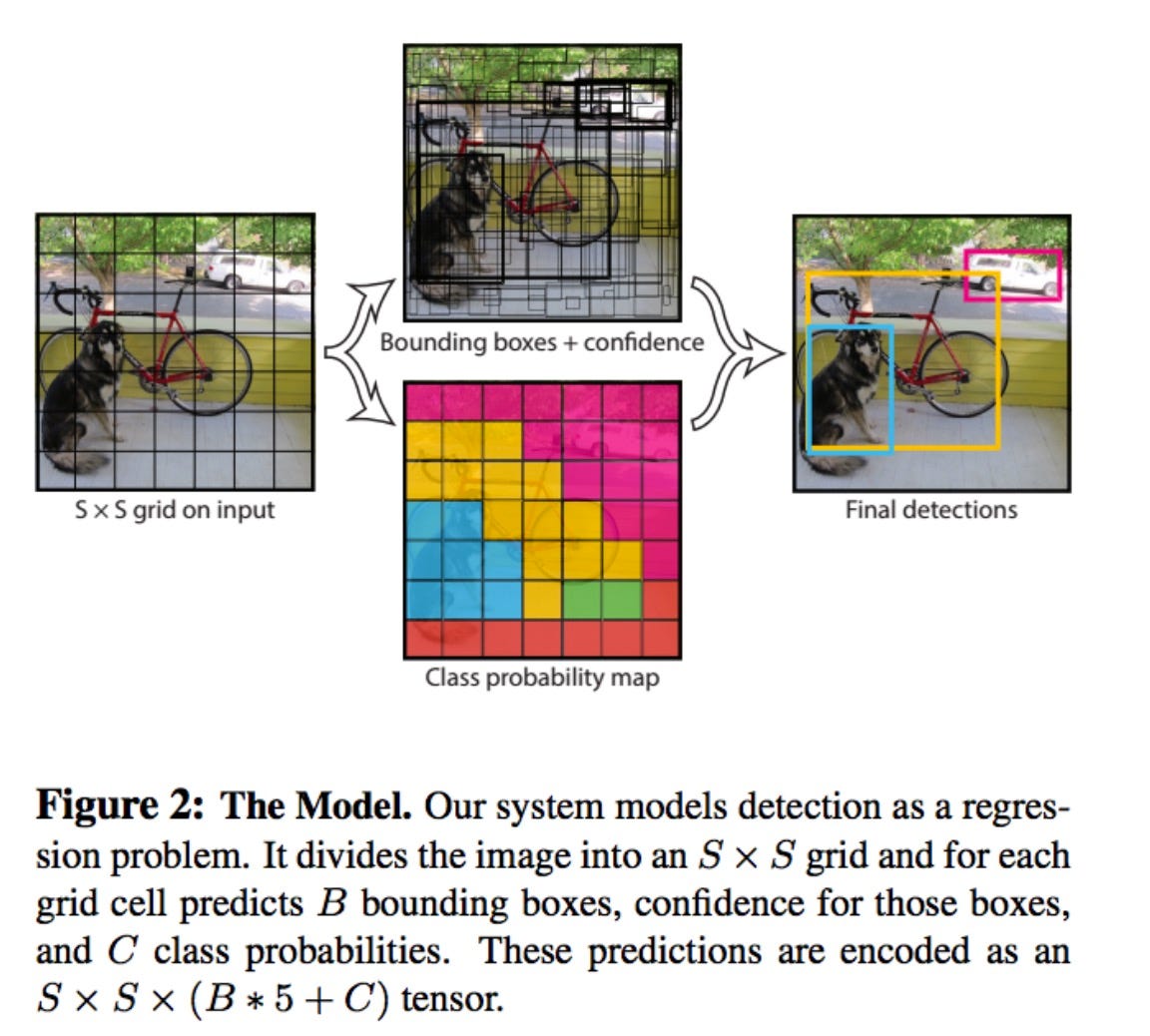
- 우선 Image를 S x S grid로 나눈다.
- 각각의 grid cell은 B개의 Bounding box에 대해 5개의 예측값을 갖는다.
($x,y$ : offset,$w,h$ : Bounding Box size, $conf$ : confidence score)
confidence score은 bounding box가 해당 cell에 포함되지 않으면 0이 된다.
- 각각의 grid cell은 C개의 class에 대해 conditional class probability를 갖는다.
(하나의 cell은 하나의 class에 대해 예측값 갖는다)
YOLO의 Architecture는 다음과 같다.
 Input size가 기존의 모델에 비해 448x448로 더욱 크다는 것을 알 수 있다. 그리고 중간의 Convolution layer들이 1x1, 3x3등 여러 size를 같이 사용하는 것이 Inception module과 비슷하다.
Input size가 기존의 모델에 비해 448x448로 더욱 크다는 것을 알 수 있다. 그리고 중간의 Convolution layer들이 1x1, 3x3등 여러 size를 같이 사용하는 것이 Inception module과 비슷하다.
그러나 속도가 빠르고 backgorund에 대해 예측도 잘하는데도 불구하고 YOLO가 가지는 한계점은
- 각 cell은 2개의 bounding box와 하나의 class probability만을 예측한다.
따라서 작은 물체들에 대해서는 예측률이 낮다.
- Loss fuction이 작은 bounding box와 큰 bounding box에 대해 error를 동일 하게 다루기 때문에, Scoring에 부적합 하다.
- 몇 단계를 거친 feature map에 대해서 예측하기 때문에, Localization이 부정확해 질 수 있다.
출처
CNN을 활용한 주요 Model - (2) : Image Detection
CNN을 활용한 최초의 기본적인 Model들 부터 계속해서 다양한 구조를 가지는 많은 모델들이 계속해서 나오고 있다. 이번 포스트에서는 아래의 분류를 기준으로 CNN의 주요 모델들에 대해서 하나씩 알아 보도록 하겠다.
- Modern CNN
- LeNet
- AlexNet
- VGG Nets
- GoogLeNet
- ResNet
- Image Detection
- RCNN
- Fast RCNN
- Faster RCNN
- SPP Net
- Yolo
- SDD
- Attention Net
- Semantic Segmentation
- FCN
- DeepLab v1, v2
- U-Net
- ReSeg
- Image Captioning
Computer vision분야에는 다양한 문제들이 있다. 우선 Computer Vision의 Task들에 대해서 먼저 알아보자.
- Classification이란, Object가 하나있는 image에 대해서 Object의 class를 분류하는 문제이다.
- Classification과 Localization을 합친 문제는 Object의 class 분류와 object의 위치는 bounding box로 위치를 찾는 문제다.
- Object Detection은 우선 Image에 있어 single object가 아닌 multiple object를 다루는 문제다. 각각의 Object에 대해 class를찾고 위치를 찾는 문제다.
- Image Segmentation이란 Object Detection과 유사하지만, 다른점은 Object의 위치를 bounding box를 통해 나타내는것이 아닌 Object의 실제 edge를 찾아 정확한 형체까지 찾아 내는 문제이다.
이번 포스트에서는 Image Detection에서 사용된 CNN 모델들에 대해서 보도록한다.
- RCNN, Fast RCNN, Faster RCNN
2013년의 RCNN의 등장이후 Fast RCNN, Faster RCNN 까지 RCNN모델들은 많은 사람들에게 영향을 주었으며, Computer Vision분야에서 가장 Impactful한 network라 할 수 있다.
RCNN
RCNN의 목적은 Object Detection 문제를 풀기 위함이다. 어떠한 이미지가 주어지면, 그 이미지에 있는 모든 Object들에 대해 Bounding box를 그리는 것이 최종 목적이다. 따라서 문제는 두가지 과정으로 나뉜다. 첫 번째, Resion Proposal과정과 Classification과정으로 나뉜다.
RCNN은 Selective Search를 사용한다. Selective Search란 Image에 대해서 2000개 정도의 각각 다른 region을 생성해낸 후 물체가 들어가 있을 확률이 가장 높은 것을 뽑는 과정이다. 이렇게 Region을 뽑아내는 Region proposal 과정을 거친 후 bounding된 Image들에 대해 AlexNet을 통과시켜 Feature extraction 과정을 거친다.(Image들은 AlexNet에 넣기 위해 227x227크기로 reshape한다) 이때 AlexNet을 통과시켜 나오는 최종 Output값을 뽑는 것이 아니라, 최종 출력층 이전 두 번째 FC Layer의 output 값인 4,096크기의 vector를 뽑는 것이다. 4,096크기의 vector에 대해 linear SVM(각 class들에 대해 사전 학습 된)을 통해 각 Region을 Scoring한다. 마지막으로 각 region들에 대해 Non-Maximum Suppression(NMS)를 사용해 bounding box를 구한다.
다시한번 과정을 정리하면
- Selective Search Algorithms을 통해 2000개정도의 region을 생성한다.
- 각각의 region들을 228x228 크기로 Reshape한다.
- reshape한 image들을 AlexNet을 통과시켜 마지막 output이전의 FC Layer의 output인 4,096크기의 vector를 뽑아낸다.
- 뽑아낸 vector를 SVM을 통해 classification을 한다.
RCNN의 Process를 보다보면 생각보다 복잡하며, 과도한 연산 및 손실되는 정보가 많은 것 같다는 생각이 든다. 실제로 2000개 정도의 region에 대해 연산을 실행하면서 연산량이 늘어나며 image를 reshape하며 손실되는 정보들 또한 많다는 단점이 있다.
Fast-RCNN
Fast-RCNN은 기존의 RCNN모델의 주요한 문제들을 해결하기 위해 나왔다.
- RCNN은 학습을 위해 최소한 3가지 과정을 거쳐야한다.(CNN, SVM, region regression) 따라서 연산량이 매우 높아져서 속도가 매우느려 실제로 사용하기에 어렵다.
Fast RCNN의 과정을 설명하면
- Image를 ConvNet을 통과시켜 ConvNet의 마지막 Feature map을 region proposal의 feature로 얻는다.
- RoI Pooling layer를 통해 각각의 Bounding box에 대해 fixed-size의 feature vector를 얻는다.
- 마지막으로 feature vector에 대해 FC layer를 통해 class label과 bounding box location을 output으로 받는다.
여기서 처음에 통과시키는 ConvNet에서 Bounding box를 얻는 과정은 SPP Net의 방법과 유사하다. SPP Net에 대해서는 아래에서 보도록 하겠다.
Faster-RCNN
Faster RCNN은 RCNN과 Faster RCNN의 복잡한 학습과정 때문에 나오게 되었다. 여기서는 Region proposal network가 Convolution layer로 feature map을 뽑은 이후 나온다. Region Proposal Network외의 나머지 pipeline은 Fast-RCNN의 것과 똑같다.(ROI, FC, Classification, Regression)
- SPP Net
SPP Net이란, Spatial Pyramid Pooling Network의 준말이다.
SPPNet은 RCNN이 나온 후 등장한 Network이다. RCNN에서는 region을 여러개 뽑은 후 CNN에 넣게 되는데, CNN에 Input값으로 넣기 위해서는 fixed-size의 image가 되어야한다. 이 과정에서 많은 정보들이 손실되는 문제점이 발생한다. 따라서 region을 만든후 Convlution layer를 통과시키는 것이 아니라, 먼저 Convolution layer를 통과시킨다. 이때 각각의 filter들은 다양한 size의 feature map들을 만든다. 이렇게 만들어진 다양한 size의 map에 대해서 feature extraction을 수행한다.
그다음 SPP Net에서 사용한 중요한 구조는 이름에서도 알 수 있듯이 Spatial Pyramid Pooling Layer이다. 이전의 다양한 size에서 Extracted feature들을 SPP Layer를 통과시킨 후 FC-layer를 통해 최종 Output값을 얻는다.
가장 중요한 SPP Layer에 대해서 살펴보자.
SPP Layer에서는 Conv Layer에서 나온 feature map들에 대해서 다양한 사이즈로 pooling을 진행한다.(1x1, 2x2, 3x3 등) 다양한 크기로 Pooling을 한 뒤 이 값들을 하나의 vector로 만들어준다.
이러한 과정을 통해 SPP Net은 RCNN에 비해 월등히 빠른 속도를 가지고 있다. 그럼에도 불구하고 학습이 어렵다는 단점과 여전히 Pipeline이 복잡하다는 단점이 존재한다.
- YOLO
YOLO란 우리가 흔히 You Only Look Once의 약자로 기존의 Object detection 알고리즘들의 속도가 real-time으로 사용하기에는 느리다는 문제점을 해결하기 위해 나온 알고리즘이다. YOLO의 가장 큰 특징은 이름에서 나오듯이 Image를 bounding box를 찾을때와 classification을 따로하는 것이 아니라 두가지를 한번에 한다는 것이다.
YOLO의 실행 과정에 대해 소개하면,
- 우선 Image를 S x S grid로 나눈다.
- 각각의 grid cell은 B개의 Bounding box에 대해 5개의 예측값을 갖는다. ($x,y$ : offset,$w,h$ : Bounding Box size, $conf$ : confidence score) confidence score은 bounding box가 해당 cell에 포함되지 않으면 0이 된다.
- 각각의 grid cell은 C개의 class에 대해 conditional class probability를 갖는다. (하나의 cell은 하나의 class에 대해 예측값 갖는다)
YOLO의 Architecture는 다음과 같다.
Input size가 기존의 모델에 비해 448x448로 더욱 크다는 것을 알 수 있다. 그리고 중간의 Convolution layer들이 1x1, 3x3등 여러 size를 같이 사용하는 것이 Inception module과 비슷하다.
그러나 속도가 빠르고 backgorund에 대해 예측도 잘하는데도 불구하고 YOLO가 가지는 한계점은
- 각 cell은 2개의 bounding box와 하나의 class probability만을 예측한다. 따라서 작은 물체들에 대해서는 예측률이 낮다.
- Loss fuction이 작은 bounding box와 큰 bounding box에 대해 error를 동일 하게 다루기 때문에, Scoring에 부적합 하다.
- 몇 단계를 거친 feature map에 대해서 예측하기 때문에, Localization이 부정확해 질 수 있다.
출처
Comments