
CNN을 활용한 주요 Model - (3) : Image Detection-2
27 Jun 2018 | CNN
CNN을 활용한 주요 Model - (3) : Image Detection-2
CNN을 활용한 최초의 기본적인 Model들 부터 계속해서 다양한 구조를 가지는 많은 모델들이 계속해서 나오고 있다. 이번 포스트에서는 아래의 분류를 기준으로 CNN의 주요 모델들에 대해서 하나씩 알아 보도록 하겠다.
- Modern CNN
- LeNet
- AlexNet
- VGG Nets
- GoogLeNet
- ResNet
- Image Detection
- RCNN
- Fast RCNN
- Faster RCNN
- SPP Net
- Yolo
- SDD
- Attention Net
- Semantic Segmentation
- FCN
- DeepLab v1, v2
- U-Net
- ReSeg
- Image Captioning
지난 포스트에 이어서 Image Detection에 사용된 Model들에 대해서 알아보도록 하겠다.
이번에 소개될 모델들은 지난 모델에 대해 좀 더 최신의 모델들로 성능 및 속도가 향상되었다는 것을 알 수 있다.
- YOLO
딥러닝에서의 YOLO란 우리가 흔히 알고 있는 You Only Live Once의 약자가 아닌 You Only Look Once의 약자로 기존의 Object detection 알고리즘들의 속도가 real-time으로 사용하기에는 느리다는 문제점을 해결하기 위해 나온 알고리즘이다.
YOLO의 가장 큰 특징은 이름에서 나오듯이 Image를 bounding box를 찾을때와 classification을 따로하는 것이 아니라 두가지를 한번에 한다는 것이다.
YOLO의 실행 과정에 대해 소개하면,
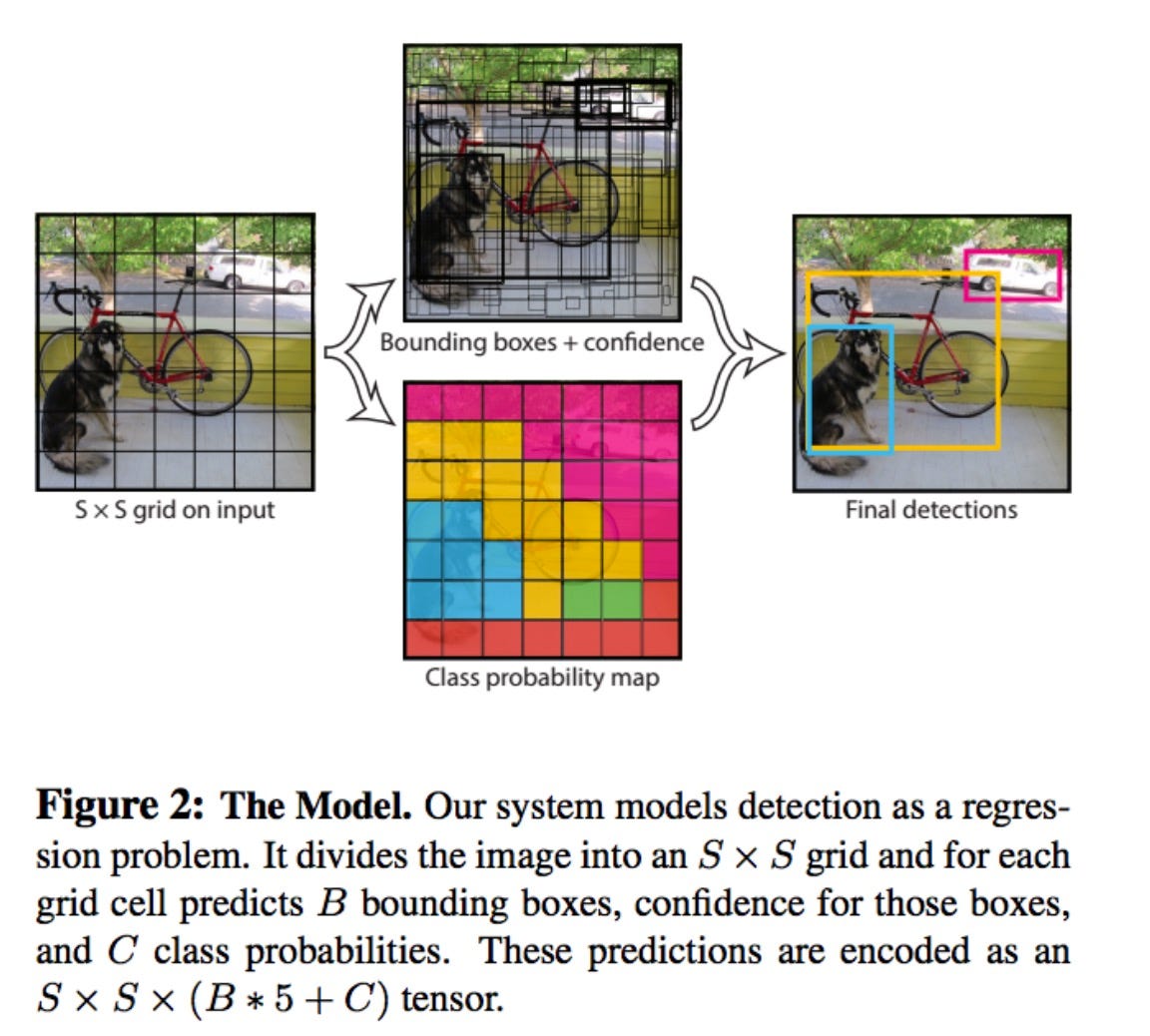
- 우선 Image를 S x S grid로 나눈다.
- 각각의 grid cell은 B개의 Bounding box에 대해 5개의 예측값을 갖는다.
($x,y$ : offset,$w,h$ : Bounding Box size, $conf$ : confidence score)
confidence score은 bounding box가 해당 cell에 포함되지 않으면 0이 된다.
- 각각의 grid cell은 C개의 class에 대해 conditional class probability를 갖는다.
(하나의 cell은 하나의 class에 대해 예측값 갖는다)
YOLO의 Architecture는 다음과 같다.
 Input size가 기존의 모델에 비해 448x448로 더욱 크다는 것을 알 수 있다. 그리고 중간의 Convolution layer들이 1x1, 3x3등 여러 size를 같이 사용하는 것이 Inception module과 비슷하다.
Input size가 기존의 모델에 비해 448x448로 더욱 크다는 것을 알 수 있다. 그리고 중간의 Convolution layer들이 1x1, 3x3등 여러 size를 같이 사용하는 것이 Inception module과 비슷하다.
그러나 속도가 빠르고 backgorund에 대해 예측도 잘하는데도 불구하고 YOLO가 가지는 한계점은
- 각 cell은 2개의 bounding box와 하나의 class probability만을 예측한다.
따라서 작은 물체들에 대해서는 예측률이 낮다.
- Loss fuction이 작은 bounding box와 큰 bounding box에 대해 error를 동일 하게 다루기 때문에, Scoring에 부적합 하다.
- 몇 단계를 거친 feature map에 대해서 예측하기 때문에, Localization이 부정확해 질 수 있다.
- SSD
기존의 detection 모델들은 Bounding box를 만들고 각 box에 있는 feature를 extract한 후 classifier를 적용합니다. 하지만 이러한 과정은 real-time으로 적용하기에 느리고, 임베디드화 시키기에도 연산량이 너무 많다는 단점이 있다. 그에 반해 YOLO는 빠르다는 장점이 있지만 정확도가 떨어진다는 단점이 있다. SSD는 이러한 단점까지 보안한 Model이다. 각 모델들의 연산량과 정확도를 확인해보면,
- Faster R-CNN : 7FPS, mAP 73.2% on VOC 2007
- YOLO : 45FPS, mAP 63.4%
- SSD : 59FPS, mAP 74.3%
(FPS : Frame Per Second, mAP : mean AP)
SSD의 구조는 특별한 것이 아니라 기존의 Feed-Forward Convolutional Network에서 feature map까지를 하나로 보고 보조적 도구 몇 가지를 더하였다.
이 기본 구조는 VGG-16 network 에서 conv5_3까지를 잘라서 사용하였다.

SSD의 핵심은 다수의 conv feature map의 각 cell으로부터 category score와 box offset값을 예측하는 것이다.
- Attention Net
Attention Net은 기존의 multiple detection이 아닌 single object에 대해 detection을 하는 model이다. 하나의 Object만 detect함에도 불구하고 이 모델이 의미있는 이유는 다음과 같다.
- 정확한 Bounding Box를 얻을 수 있다.
- 높은 성능
- 간단한 구조

기존의 모델에서 detection은 Object에 대해 알맞는 Bounding box를 찾는 문제 였지만, Attention Net에서는 Bounding box 크기를 조정하며 Object에 딱 맞는 Bounding box를 찾는 과정이라 할 수 있다.
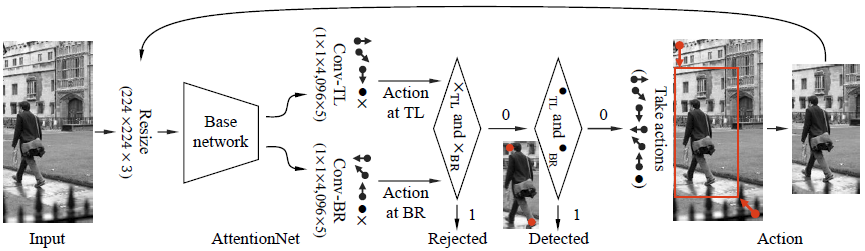
Attention Net의 과정은 다음과 같다.
- Input Image를 고정된 사이즈로 Reshape한다.
- reshape된 image를 Convolution layer들을 통과시켜 크기 5의 2개의 벡터를 얻는다.
각각의 벡터는 Bounding box의 좌측 상단(TL), 좌측 하단(BR)에 대한 예측값이다.
- 이후 예측 값을 알맞게 예측됬는지를 확인하는 두개의 층을 통과시킨다.
(예측이 제대로 되지 않았다면 다시 bounding box를 조정해 반복한다)
출처
CNN을 활용한 주요 Model - (3) : Image Detection-2
CNN을 활용한 최초의 기본적인 Model들 부터 계속해서 다양한 구조를 가지는 많은 모델들이 계속해서 나오고 있다. 이번 포스트에서는 아래의 분류를 기준으로 CNN의 주요 모델들에 대해서 하나씩 알아 보도록 하겠다.
- Modern CNN
- LeNet
- AlexNet
- VGG Nets
- GoogLeNet
- ResNet
- Image Detection
- RCNN
- Fast RCNN
- Faster RCNN
- SPP Net
- Yolo
- SDD
- Attention Net
- Semantic Segmentation
- FCN
- DeepLab v1, v2
- U-Net
- ReSeg
- Image Captioning
지난 포스트에 이어서 Image Detection에 사용된 Model들에 대해서 알아보도록 하겠다. 이번에 소개될 모델들은 지난 모델에 대해 좀 더 최신의 모델들로 성능 및 속도가 향상되었다는 것을 알 수 있다.
- YOLO
딥러닝에서의 YOLO란 우리가 흔히 알고 있는 You Only Live Once의 약자가 아닌 You Only Look Once의 약자로 기존의 Object detection 알고리즘들의 속도가 real-time으로 사용하기에는 느리다는 문제점을 해결하기 위해 나온 알고리즘이다. YOLO의 가장 큰 특징은 이름에서 나오듯이 Image를 bounding box를 찾을때와 classification을 따로하는 것이 아니라 두가지를 한번에 한다는 것이다.
YOLO의 실행 과정에 대해 소개하면,
- 우선 Image를 S x S grid로 나눈다.
- 각각의 grid cell은 B개의 Bounding box에 대해 5개의 예측값을 갖는다. ($x,y$ : offset,$w,h$ : Bounding Box size, $conf$ : confidence score) confidence score은 bounding box가 해당 cell에 포함되지 않으면 0이 된다.
- 각각의 grid cell은 C개의 class에 대해 conditional class probability를 갖는다. (하나의 cell은 하나의 class에 대해 예측값 갖는다)
YOLO의 Architecture는 다음과 같다.
Input size가 기존의 모델에 비해 448x448로 더욱 크다는 것을 알 수 있다. 그리고 중간의 Convolution layer들이 1x1, 3x3등 여러 size를 같이 사용하는 것이 Inception module과 비슷하다.
그러나 속도가 빠르고 backgorund에 대해 예측도 잘하는데도 불구하고 YOLO가 가지는 한계점은
- 각 cell은 2개의 bounding box와 하나의 class probability만을 예측한다. 따라서 작은 물체들에 대해서는 예측률이 낮다.
- Loss fuction이 작은 bounding box와 큰 bounding box에 대해 error를 동일 하게 다루기 때문에, Scoring에 부적합 하다.
- 몇 단계를 거친 feature map에 대해서 예측하기 때문에, Localization이 부정확해 질 수 있다.
- SSD
기존의 detection 모델들은 Bounding box를 만들고 각 box에 있는 feature를 extract한 후 classifier를 적용합니다. 하지만 이러한 과정은 real-time으로 적용하기에 느리고, 임베디드화 시키기에도 연산량이 너무 많다는 단점이 있다. 그에 반해 YOLO는 빠르다는 장점이 있지만 정확도가 떨어진다는 단점이 있다. SSD는 이러한 단점까지 보안한 Model이다. 각 모델들의 연산량과 정확도를 확인해보면,
- Faster R-CNN : 7FPS, mAP 73.2% on VOC 2007
- YOLO : 45FPS, mAP 63.4%
- SSD : 59FPS, mAP 74.3% (FPS : Frame Per Second, mAP : mean AP)
SSD의 구조는 특별한 것이 아니라 기존의 Feed-Forward Convolutional Network에서 feature map까지를 하나로 보고 보조적 도구 몇 가지를 더하였다. 이 기본 구조는 VGG-16 network 에서 conv5_3까지를 잘라서 사용하였다.
SSD의 핵심은 다수의 conv feature map의 각 cell으로부터 category score와 box offset값을 예측하는 것이다.
- Attention Net
Attention Net은 기존의 multiple detection이 아닌 single object에 대해 detection을 하는 model이다. 하나의 Object만 detect함에도 불구하고 이 모델이 의미있는 이유는 다음과 같다.
- 정확한 Bounding Box를 얻을 수 있다.
- 높은 성능
- 간단한 구조
기존의 모델에서 detection은 Object에 대해 알맞는 Bounding box를 찾는 문제 였지만, Attention Net에서는 Bounding box 크기를 조정하며 Object에 딱 맞는 Bounding box를 찾는 과정이라 할 수 있다.
Attention Net의 과정은 다음과 같다.
- Input Image를 고정된 사이즈로 Reshape한다.
- reshape된 image를 Convolution layer들을 통과시켜 크기 5의 2개의 벡터를 얻는다. 각각의 벡터는 Bounding box의 좌측 상단(TL), 좌측 하단(BR)에 대한 예측값이다.
- 이후 예측 값을 알맞게 예측됬는지를 확인하는 두개의 층을 통과시킨다. (예측이 제대로 되지 않았다면 다시 bounding box를 조정해 반복한다)
출처
Comments