
Word2Vec (2) : Skip Gram 모델 & 튜닝 기법
24 Jul 2018 | NLP
- Word Embedding & Word2Vec(CBOW model) (이전 포스트)
- Word2Vec(Skip-Gram) & 튜닝 기법
Skip-Gram
이제는 Word2Vec의 두 번째 모델인 Skip-Gram 모델에 대해서 알아보도록 한다. CBOW와 비슷한 아이디어지만 반대의 개념이다. CBOW는 주변 단어들을 통해서 중간의 단어를 예측하는 모델이였다면 Skip-Gram은 중심 단어를 통해 주변단어를 예측하는 모델이다. 아래 예시를 보자.
__ __ __ 배가 __ __ __ __
위의 예시와 같이 중간의 단어를 통해 주변단어를 예측하는 모델이다. 아키텍쳐 또한 CBOW와 반대라고 생각하면 된다. 아래 그림을 보자.

Skip-Gram 모델이 진행되는 과정에 대해서 알아보자.
가운데 단어를 one-hot vector로 만들어 준다.
다음으로 파라미터 매트릭스인 $\mathbf{W}_{V\times N}$를 중간 단어 one-hot vector에 곱해줘서 embedded vector를 구한다.
embedded vector를 두 번째 파라미터 매트릭스인 $\mathbf{W^{\prime}}$를 곱해서 score vector를 계산한다.
이제 위에서 구한 각 score vector에 대해서 확률값으로 만들어 준다.
Skip-Gram의 모델의 경우 context의 주변 단어 모두를 예측하기 때문에 확률 값이 다음과 같이 $2m$개 나올것이다.
이제 구한 확률값에 대해서 각 위치의 정답과 비교한다.
이제 학습을 위해 Objective function은 다음과 같이 정의하고 최소화 할 것이다.
여기서 중요한 CBOW와의 차이점은 우리가 각 단어에 대해 독립이라고 가정을 한다는 것이다. 즉 중심 단어에 대해 주변 단어들을 완벽하게 독립적이라고 가정하는 것이다.
CBOW 모델과 같이 확률값을 cross-entropy함수로 정의된다.
여기서 $H()$가 cross entropy가 된다.
여기까지가 Skip-Gram에 대한 소개다. 하지만 이번 포스트에서는 skip-gram을 좀 더 빠르고 효율적으로 만드는 세가지 기법에 대해서 소개한다.
Subsampling Frequent words
Skip-Gram모델은 중심 단어에 대해서 주변 단어를 예측하며 Update하기 때문에 CBOW모델보다 각 단어에 대해서 update 기회가 더 많다(SkipGram모델을 CBOW보다 많이 쓰는 이유이기도 하다.). 아래 그림을 보면 Skip-Gram이 학습을 진행하는 과정에 대해서 볼 수 있다.
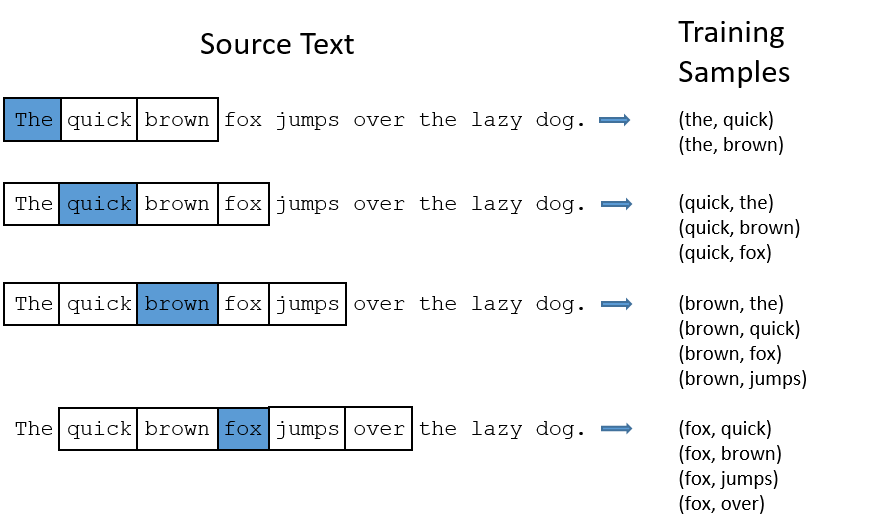
학습 과정을 보면 단어 “the”와 다른 단어들이 같이 trainning되는 경우가 많다는 것을 볼 수 있다. 이 그림은 하나의 Sentence에 대해서 본 것이지만 실제 학습은 전체 Data에 대해서 진행 할 것이다. Data안에서 “the” 라는 단어와 함께 update 되는 것들이 얼마나 많을지 생각해보자. 단어의 특성상 Data안에서 매우 자주 등장할 것이고 그 만큼 update되는 횟수도 많은 것이다. 하지만 update되는 횟수에 비해 “the”라는 단어가 의미적으로 중요하지도 않다. 이러한 경우 학습시간만 증가시킬뿐 학습 정확도에는 크게 기여하지 않는다. 이런 문제를 해결하는 방법이 Subsampling Frequent words이다.
Subsampling하는 방법은 학습시에 단어들을 무작위로 제외시키는 것이다. 만약 자주 등장하는 단어라면 더 자주 제외시켜야한다. 단어별로 제외되는 확률은 다음과 같이 정의된다.
위 식에서 $f()$는 각 단어의 전체 Data에서 출현하는 횟수이다. 즉 자주등장하는 단어일수록 확률값을 줄어들게 된다. 그리고 $t$는 HyperParameter값으로 논문의 연구진들은 $t$값으로 $0.00001(10^{-5})$ 값을 추천한다.
Negative Sampling
그리고 Skip-Gram모델의 Objective function을 다시 한번 보자. Summation이 $|V|$번 돌고 있다는 것을 볼 수 있다. $|V|$은 vocabulary의 크기로 단어의 개수는 수만에서 수백만 까지도 될 수 있다는 점을 기억하자. 직관적으로 봐도 이 식을 계산하는 것은 매우 오래걸릴 것 같다. 실제로도 오래걸린다.
그렇다면 학습 과정에서 속도를 올려줄 수 있는 방법은 무었일까?
방법은 정확한 계산을 하지 않고 계산량을 줄인 다음 근사시키는 방법이다. 이러한 방법 중 하나인 Negative Samgpling 방법에 대해서 소개한다.
Negative Sampling의 방법은 다음과 같다. 기존의 확률계산(Softmax 계산)에서는 모든단어에 대해서 전체 경우를 구했지만, 여기서는 현재 Window내에서 등장하지 않는단어를 특정개수만 뽑아서 확률을 계산하는 것이다. 예를들면 Window size가 5라면 window내에 등장하지 않는 Data내의 다른 단어 5~25개 정도의 단어를뽑아서 확률을 계산하는 것이다.
Negative Sampling을 사용하기위해 Objective function을 다시 정의한다.
여기서 확률 $P()$는 ‘Unigram Distribution’이며 다음과 같이 정의한다.
3/4같은 수는 고정값으로 논문에 따르면 다른 값들에 비해 성능을 가장 잘 내는 값이라고 한다.
Hierarchical Softmax
Hierarchical Softmax는 기존의 계산량이 많은 Softmax함수 대신 사용해서 계산량을 줄이는 방법 중 하나이다. 이름 그대로 Softmax를 전체로 계산하기 보다는 Tree구조로 Hierarchical하게 Softmax를 계산한다. 먼저 그림을 보자.
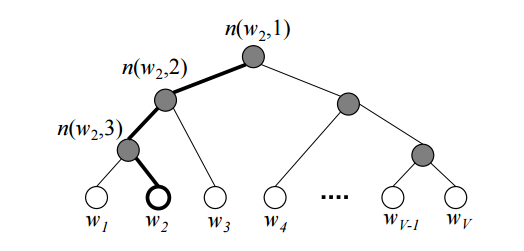
각 단어에 대해 Softmax를 계산하려면 우선 node값부터 해당 word까지 내려가면서 각 값을 곱하는 방법이다. Hierarchical의 계산과정에 대한 자세한 설명을 생략한다. 자세히 알고 싶다면 이 링크를 통해 확인하자.
Hierarchical Softmax와 Negative Sampling은 확률 값 계산의 계산량을 줄이기 위한 방법으로 목적이 같다. 따라서 택일하여 사용해야한다.
- Word Embedding & Word2Vec(CBOW model) (이전 포스트)
- Word2Vec(Skip-Gram) & 튜닝 기법
Skip-Gram
이제는 Word2Vec의 두 번째 모델인 Skip-Gram 모델에 대해서 알아보도록 한다. CBOW와 비슷한 아이디어지만 반대의 개념이다. CBOW는 주변 단어들을 통해서 중간의 단어를 예측하는 모델이였다면 Skip-Gram은 중심 단어를 통해 주변단어를 예측하는 모델이다. 아래 예시를 보자.
__ __ __ 배가 __ __ __ __
위의 예시와 같이 중간의 단어를 통해 주변단어를 예측하는 모델이다. 아키텍쳐 또한 CBOW와 반대라고 생각하면 된다. 아래 그림을 보자.
Skip-Gram 모델이 진행되는 과정에 대해서 알아보자.
가운데 단어를 one-hot vector로 만들어 준다.
다음으로 파라미터 매트릭스인 $\mathbf{W}_{V\times N}$를 중간 단어 one-hot vector에 곱해줘서 embedded vector를 구한다.
embedded vector를 두 번째 파라미터 매트릭스인 $\mathbf{W^{\prime}}$를 곱해서 score vector를 계산한다.
이제 위에서 구한 각 score vector에 대해서 확률값으로 만들어 준다.
Skip-Gram의 모델의 경우 context의 주변 단어 모두를 예측하기 때문에 확률 값이 다음과 같이 $2m$개 나올것이다.
이제 구한 확률값에 대해서 각 위치의 정답과 비교한다.
이제 학습을 위해 Objective function은 다음과 같이 정의하고 최소화 할 것이다. 여기서 중요한 CBOW와의 차이점은 우리가 각 단어에 대해 독립이라고 가정을 한다는 것이다. 즉 중심 단어에 대해 주변 단어들을 완벽하게 독립적이라고 가정하는 것이다.
CBOW 모델과 같이 확률값을 cross-entropy함수로 정의된다.
여기서 $H()$가 cross entropy가 된다. 여기까지가 Skip-Gram에 대한 소개다. 하지만 이번 포스트에서는 skip-gram을 좀 더 빠르고 효율적으로 만드는 세가지 기법에 대해서 소개한다.
Subsampling Frequent words
Skip-Gram모델은 중심 단어에 대해서 주변 단어를 예측하며 Update하기 때문에 CBOW모델보다 각 단어에 대해서 update 기회가 더 많다(SkipGram모델을 CBOW보다 많이 쓰는 이유이기도 하다.). 아래 그림을 보면 Skip-Gram이 학습을 진행하는 과정에 대해서 볼 수 있다.
학습 과정을 보면 단어 “the”와 다른 단어들이 같이 trainning되는 경우가 많다는 것을 볼 수 있다. 이 그림은 하나의 Sentence에 대해서 본 것이지만 실제 학습은 전체 Data에 대해서 진행 할 것이다. Data안에서 “the” 라는 단어와 함께 update 되는 것들이 얼마나 많을지 생각해보자. 단어의 특성상 Data안에서 매우 자주 등장할 것이고 그 만큼 update되는 횟수도 많은 것이다. 하지만 update되는 횟수에 비해 “the”라는 단어가 의미적으로 중요하지도 않다. 이러한 경우 학습시간만 증가시킬뿐 학습 정확도에는 크게 기여하지 않는다. 이런 문제를 해결하는 방법이 Subsampling Frequent words이다.
Subsampling하는 방법은 학습시에 단어들을 무작위로 제외시키는 것이다. 만약 자주 등장하는 단어라면 더 자주 제외시켜야한다. 단어별로 제외되는 확률은 다음과 같이 정의된다.
위 식에서 $f()$는 각 단어의 전체 Data에서 출현하는 횟수이다. 즉 자주등장하는 단어일수록 확률값을 줄어들게 된다. 그리고 $t$는 HyperParameter값으로 논문의 연구진들은 $t$값으로 $0.00001(10^{-5})$ 값을 추천한다.
Negative Sampling
그리고 Skip-Gram모델의 Objective function을 다시 한번 보자. Summation이 $|V|$번 돌고 있다는 것을 볼 수 있다. $|V|$은 vocabulary의 크기로 단어의 개수는 수만에서 수백만 까지도 될 수 있다는 점을 기억하자. 직관적으로 봐도 이 식을 계산하는 것은 매우 오래걸릴 것 같다. 실제로도 오래걸린다.
그렇다면 학습 과정에서 속도를 올려줄 수 있는 방법은 무었일까? 방법은 정확한 계산을 하지 않고 계산량을 줄인 다음 근사시키는 방법이다. 이러한 방법 중 하나인 Negative Samgpling 방법에 대해서 소개한다.
Negative Sampling의 방법은 다음과 같다. 기존의 확률계산(Softmax 계산)에서는 모든단어에 대해서 전체 경우를 구했지만, 여기서는 현재 Window내에서 등장하지 않는단어를 특정개수만 뽑아서 확률을 계산하는 것이다. 예를들면 Window size가 5라면 window내에 등장하지 않는 Data내의 다른 단어 5~25개 정도의 단어를뽑아서 확률을 계산하는 것이다.
Negative Sampling을 사용하기위해 Objective function을 다시 정의한다.
여기서 확률 $P()$는 ‘Unigram Distribution’이며 다음과 같이 정의한다.
3/4같은 수는 고정값으로 논문에 따르면 다른 값들에 비해 성능을 가장 잘 내는 값이라고 한다.
Hierarchical Softmax
Hierarchical Softmax는 기존의 계산량이 많은 Softmax함수 대신 사용해서 계산량을 줄이는 방법 중 하나이다. 이름 그대로 Softmax를 전체로 계산하기 보다는 Tree구조로 Hierarchical하게 Softmax를 계산한다. 먼저 그림을 보자.
각 단어에 대해 Softmax를 계산하려면 우선 node값부터 해당 word까지 내려가면서 각 값을 곱하는 방법이다. Hierarchical의 계산과정에 대한 자세한 설명을 생략한다. 자세히 알고 싶다면 이 링크를 통해 확인하자.
Hierarchical Softmax와 Negative Sampling은 확률 값 계산의 계산량을 줄이기 위한 방법으로 목적이 같다. 따라서 택일하여 사용해야한다.
Comments