
Transformer: Attention is all you need
08 Sep 2018 | NLP
이번에 리뷰할 논문은 Google에서 발표한 Attention is all you need이다. 논문 이름부터 어떤 내용을 다룰지 짐작가게 하는데, 기존의 attention에 대해서 생각해보면 sequence to sequence 모델에서 혹은 convolutional neural network 모델에서 부가적으로 attention mechanism을 적용시켰다고 볼 수 있는데, 이 논문에서는 attention만으로 모든 모델을 만들었다는 점이 흥미롭다.
자세한 설명 이전에 간단히 설명하자면 기존의 모델들 처럼 RNN 혹은 CNN을 사용하지 않고 attention만 사용해서 연산량이 매우 줄었다. 그럼에도 불구하고 성능도 매우 높게 나오는 모델이다. Transfomer라고도 불리는데 논문을 보면서 어떻게 구성되어 있는지 자세히 알아보도록 하자.
Introduction
RNN 모델들이 주로 기계 번역 혹은 language modeling 등 sequence를 다루기 위한 모델로 많이 사용되고 있다. 하지만 이런 RNN을 활용한 모델을 문장이 길어질수록 성능이 떨어지고 memory의 제약으로 batch에도 제한이 생길 수 있다는 단점이있다. 또한 단순한 sequence to sequence 모델은 sequnece의 alignment를 해결하지 못한 문제가 아직 남아있다.
attention mechanism을 통해 위에서 언급했던 RNN 모델의 문제점을 어느정도 해결했지만 결국 대부분의 모델은 attention이 RNN과 함께 사용되는 용도로만 사용되었다.
해당 논문에서는 Transformer 라 불리는 모델을 소개한다. 다른 CNN 혹은 RNN 모델 없이 단순히 attention mechanism만으로 모델을 구성했으며 학습시간이 매우 빠르다는 장점이 있다.
Model Architecture
대부분의 sequence를 다루는 모델들은 encoder-decoder 구조로 되어있다. 여기서 encoder는 input sequence를 continuous한 representations로 바꾸고 decoder는 이 representation을 통해 output을 만들어낸다.
Transformer의 전체적인 architecture는 stacked self-attention(intra-attention)과 point-wise fc layer들을 사용해서 구성되어 있다. 아래 그림이 전체 architecture를 나타낸다. 그림에서 왼쪽이 encoder이고 오른쪽이 decoder이다.
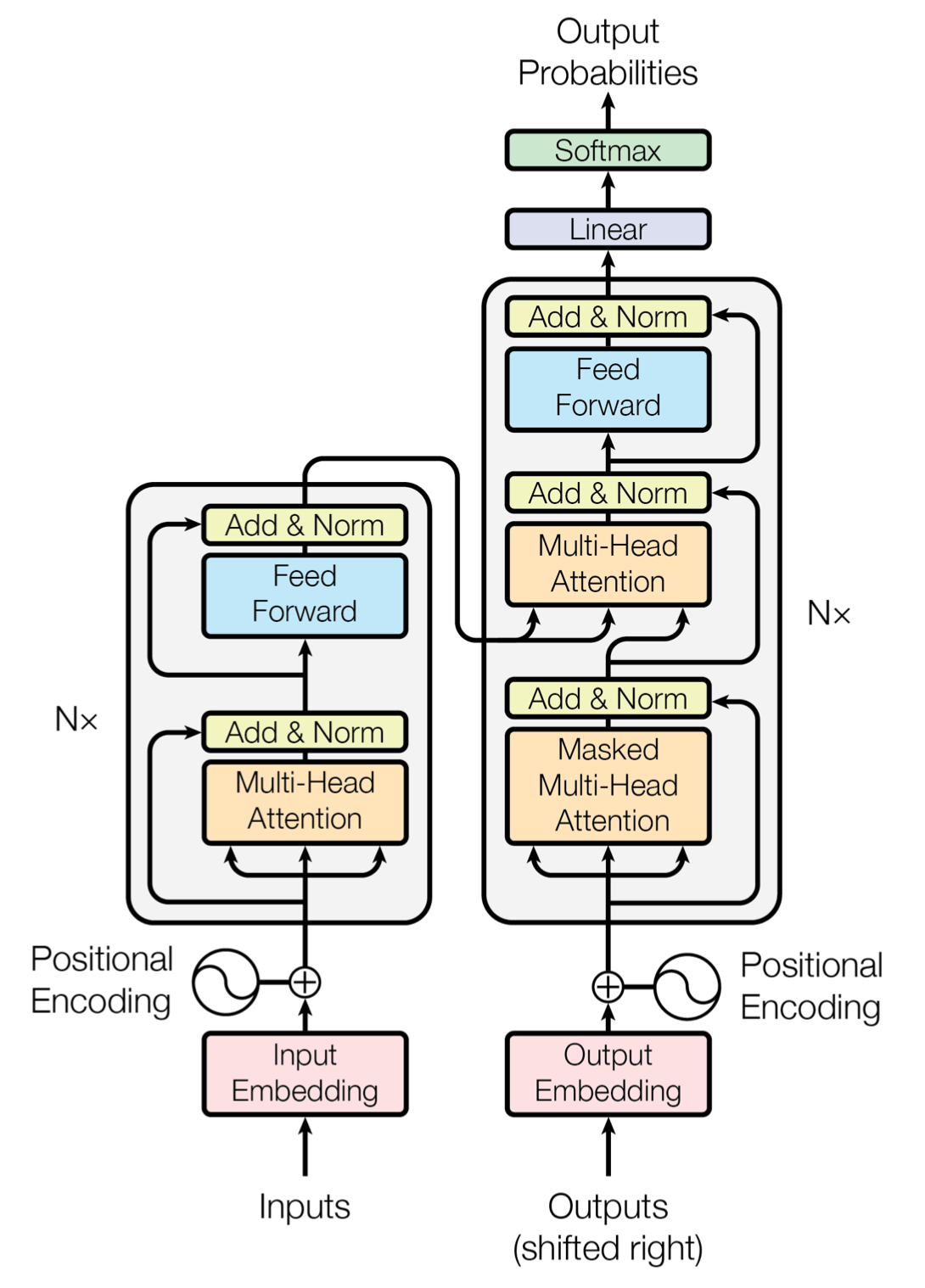
이제 모델 하나하나 자세히 알아보도록 하자.
Encoder & Decoder
Encoder
Encoder는 동일한 layer가 N개 반복되는 형태이다. 이 논문에서는 6번 반복했다. 그리고 각 layer는 두개의 sub-layer로 구성된다. 첫 sub-layer는 multi-head self-attention mechanism이고 두번쨰는 간단한 point-wise fc-layer이다. 그리고 모델 전체적으로 각 sub-layer에 residual connection을 사용했다. 그리고 residual 값을 더한 뒤에 layer 값을 Nomalize한다. 즉 각 sub-layer는 결과에 대해 residual 값을 더하고 그 값을 nomalize한 값이 output으로 나오게 된다. 그리고 모델 전체적으로 residual 계산을 쉽게하기 위해서 output의 dimension은 모두 512로 맞췄다.
Decoder
Decoder도 encoder와 마찬가지로 동일한 layer가 N개 반복되는 형태이다. 그리고 이 논문에서는 decoder도 6번 반복했다. 그러나 반복되는 layer가 encoder와는 다른 구조이다. 총 3개의 sub-layer로 구성되어 있는데, 2개는 기존의 encoder의 sub-layer와 동일하고 나머지 하나는 encoder의 ouput에 대해 multi-head attention을 계산하는 sub-layer가 추가되었다. 그림으로 보면 오른쪽의 가운데 sub-layer이다.
Decoder에서도 residual connection을 사용했다. residual 값을 더한 후 동일하게 layer nomalize를 해준다. 그리고 self-attetion을 encoder와는 약간 다르게 수정을 했는데, masking을 추가했다. self-attention시 현재 위치보다 뒤에 있는 단어는 attend 못하도록 masking을 추가해준 것이다.
Attention
이 모델에서 사용한 attention은 총 2가지 종류이다. 하나는 Scaled dot-product attention이고 나머지 하나는 Multi-head attention이다.
Scaled dot-product attention

해당 attention의 input은 3가지다. $d_k$ dimension을 가지는 queries와 keys, 그리고 $d_v$ dimension을 가지는 values로 구성된다. 우선 하나의 query에 대해 모든 key들과 dot product를 한 뒤 각 값을 로 나눠준다. 그리고 softmax함수를 씌운 후 마지막으로 value를 곱하면 attention 연산이 끝난다.
실제로 계산할때는 query, key, value를 vector하나하나 계산하는 것이 아니라 여러개를 matrix로 만들어 계산한다. 수식은 다음과 같다.
추가적인 설명
우선 query와 key, value에 대해서 설명하면 query가 어떤 단어와 관련되어 있는지 찾기 위해서 모든 key들과 연산한다. 여기서 실제 연산을 보면 query와 key를 dot-product한뒤 softmax를 취하는데, 의미하는 것은 하나의 query가 모든 key들과 연관성을 계산한뒤 그 값들을 확률 값으로 만들어 주는 것이다. 따라서 query가 어떤 key와 높은 확률로 연관성을 가지는지 알게 되는 것이다. 이제 구한 확률값을 value에 곱해서 value에 대해 scaling한다고 생각하면된다.
추가적인 설명
key와 value는 사실상 같은 단어를 의미한다. 하지만 두개로 나눈 이유는 key값을 위한 vector와 value를 위한 vector를 따로 만들어서 사용한다. key를 통해서는 각 단어와 연관성의 확률을 계산하고 value는 그 확률을 사용해서 attention 값을 계산하는 용도이다.
보통 흔히 사용되는 attention 함수는 additive attention과 dot-product(multiplicative) attention 두가지다. 후자의 경우가 현재 사용하고 있는 attention과 거의 유사하다. 다른점은 $\frac{1}{\sqrt{d_k}}$로 scailing을 하지 않았다는 점이다. 그리고 dot-product attention과 additive attention을 비교하면 dot-product attention이 속도측면에서 앞선다. 복잡도는 비슷한데 속도가 앞서는 이유는 matrix multiplication에 대한 최적화된 구현이 많이 있기 때문이다.
그리고 앞서 설명하지 않았던 것이 하나 있다. rescaling을 하는 부분인데, 만약 dimension의 루트값으로 나눠주지 않는다면 어떤 일이 생기는지 생각해보자. vector의 길이가 길어질수록, 즉 dimension이 커질수록 자연스럽게 dot-product값은 점점 더 커질 것이다. 그러나 이후에 softmax함수가 있기 때문에 back-propagation 과정에서도 미분값이 조금만 넘어오게 되서 상대적으로 학습이 느려지거나 학습이 잘안되는 상황이 발생할 수 있다. 따라서 dimension이 큰 경우를 대비해 dimension의 루트값으로 나눠준다.
Multi-head attention

기존의 attention은 전체 dimension에 대해서 하나의 attention만 적용시켰다. 여기서 사용한 Multi-head attention이란 전체 dimension에 대해서 한번 attention을 적용하는 것이 아니라 전체 dimension을 h로 나눠서 attention을 $h$번 적용시키는 방법이다.
각 query, key, value의 vector는 linearly하게 $h$개로 project 된다. 이후 각각 나눠서 attention을 시킨 후 만들어진 $h$개의 vector를 concat하면 된다. 마지막으로 vector의 dimension을 로 다시 맞춰주도록 matrix를 곱하면 끝난다. Multi-head attention을 수식으로 표현하면 다음과 같다.
각 파라미터의 shape은 다음과 같다.
해당 논문에서는 $h=8$ 즉 8개의 head를 사용했다. 따라서 각 vector들의 dimension은 다음과 같이 8로 나눠진다.
$h$번 계산했지만 각 head들이 dimension이 줄었기 때문에 전체 연산량은 비슷하다.
Applications of Attention in our Model
Transformer에서 multi-head attention을 다음과 같은 방법으로 사용했다.
- “encoder-decoder attention” layer에서 query들은 이전 decoder layer에서 온다. 그리고 encoder에서 온 key와 value를 사용한다. 따라서 decoder의 모든 위치의 token은 input sequence의 어느 곳이든 attend할 수 있게 된다.
- encoder는 self-attention layer를 가진다. 모든 key, value, query는 같은 sequence에서 온다. 정확히는 이전 layer의 output에서 온다. 따라서 encoder는 이전 layer의 전체 위치를 attend할 수 있다.
- decoder의 self-attention layer도 이전 layer의 모든 position을 attend 할 수 있는데, 정확히는 자신의 position이전의 position까지만 attend 할 수 있다. 직관적으로 이해하면 sequence에서 앞의 정보만을 참고할 수 있게 한 것이다. 이러한 목적을 scaled dot-product를 masking 함으로써 구현했다.
Position-wise Feed-Forward Networks
attention sub-layer에 이어서 fully connected feed-forward network 거치게 되는데 이 network는 두개의 linear transformation으로 구성되어 있고 두 transformation 사이에 ReLU 함수를 사용한다.
Embeddings and Softmax
다른 sequence 모델과 유사하게 embedding vector를 사용한다. 입력 token을 linear transformation 해서 dimension vector로 바꿔주고 softmax로 나온 decoder의 결과 값을 predicted next-token으로 다시 linear transformation해서 바꿔준다. 모델 전체를 보면 3번 embedding 과정(역 embedding 포함)이 있는데, 이 때 linear transofrmation에 사용되는 weight matrix는 다 같은 matrix를 사용한다. 즉 2개의 embedding layer에서의 linear transformation과 softmax 다음의 linear transormation에서 같은 matrix를 사용하는 것이다.
Positional Encoding
해당 모델에서는 recurrence나 convolution을 전혀 사용하지 않았기 떄문에, 추가적으로 위치 정보를 넣어줘야 한다. 따라서 “positional encoding”을 사용해서 input embedding에 위치 정보를 넣어준다. 각 위치에 대해서 embedding과 동일한 dimension을 가지도록 encoding을 해준 뒤 그 값을 embedding값과 더해서 사용한다.
positional encoding에는 여러 방법이 있지만 여기서는 sin, cos 함수를 사용해서 구현한다. 각 위치 $pos$와 dimension $i$에 대한 positional encoding값은 다음과 같이 구한다.
Why self-attention
이 모델에서 recurrent 나 convolution을 사용하지 않고 self-attention만을 사용한 이유에 대해서 알아보자. 3가지 이유로 self-attention을 선택했다.
- 레이어당 전체 연산량이 줄어든다.
- 병렬화가 가능한 연산이 늘어난다.
- long-range의 term들의 dependency도 잘 학습할 수 있게 된다.
그리고 위의 3가지 외에 또 다른 이유는 attention을 사용하면 모델 자체의 동작을 해석하기 쉬워진다는(interpretable) 장점 때문이다. attention 하나의 동작 뿐만 아니라 multi-head의 동작 또한 어떻게 동작하는지 이해하기 쉽다는 장점이 있다. 아래의 그림을 보면 어떻게 attention mechanism이 적용되는지 쉽게 이해할 수 있다.


Training
학습에 사용된 것들을 하나씩 알아보자.
Training data and batching
학습에 사용된 데이터는 WMT 2014 English-German 데이터 셋이다. 총 450만개의 영어-독일어 문장 쌍이 있다. 그리고 WMT 2014 English-French 데이터 셋도 사용했다. 총 360만개의 문장 쌍이 있다. 학습시 대략 25000개의 token을 포함하는 문장 쌍을 하나의 배치로 사용했다.
Optimizer
학습에 사용된 optimizer는 Adam을 사용했다. 하이퍼 파라미터로는 $\beta_1=0.9$, $\beta_2=0.98$, $\epsilon=10^{-9}$를 사용했다. 학습률(learning rate)의 경우 학습 경과에 따라서 변화하도록 만들었다. 아래의 공식으로 학습률을 계산해서 적용했다.
여기서 warmup_step의 값으로는 4000을 사용했다.
Regularization
학습 시 정규화를 위해서는 세가지 방법을 사용했다.
- Residual dropout
- Attention dropout
- label smoothing
여기서 dropout 값은 0.1로 했고, label smoothing 값도 0.1로 설정했다.
Conclusion
번역에서 Tansformer는 다른 모델들 보다 훨씬 빠르게 학습했다. 그리고 빠른 속도에도 성능에서도 이전의 모델들보다 좋은 성능을 보여줬다.
Recurrent, convolution을 전혀 사용하지 않고 attention만 사용해서 만든 모델임에도 좋은 성능을 보여줬다. 우선 이 모델이 크게 의미하는 바는 빠른 학습속도를 보여준 것이다. 따라서 앞으로도 번역 뿐만 아니라 이미지 등 큰 input을 가지는 문제에도 적용할 수 있을 것이다.
오역 및 잘못된 내용이 있을 수 있습니다. 잘못된 부분 혹은 이해가 잘 안되는 부분은 댓글 혹은 메일로 말씀해주시면 감사하겠습니다!
이번에 리뷰할 논문은 Google에서 발표한 Attention is all you need이다. 논문 이름부터 어떤 내용을 다룰지 짐작가게 하는데, 기존의 attention에 대해서 생각해보면 sequence to sequence 모델에서 혹은 convolutional neural network 모델에서 부가적으로 attention mechanism을 적용시켰다고 볼 수 있는데, 이 논문에서는 attention만으로 모든 모델을 만들었다는 점이 흥미롭다.
자세한 설명 이전에 간단히 설명하자면 기존의 모델들 처럼 RNN 혹은 CNN을 사용하지 않고 attention만 사용해서 연산량이 매우 줄었다. 그럼에도 불구하고 성능도 매우 높게 나오는 모델이다. Transfomer라고도 불리는데 논문을 보면서 어떻게 구성되어 있는지 자세히 알아보도록 하자.
Introduction
RNN 모델들이 주로 기계 번역 혹은 language modeling 등 sequence를 다루기 위한 모델로 많이 사용되고 있다. 하지만 이런 RNN을 활용한 모델을 문장이 길어질수록 성능이 떨어지고 memory의 제약으로 batch에도 제한이 생길 수 있다는 단점이있다. 또한 단순한 sequence to sequence 모델은 sequnece의 alignment를 해결하지 못한 문제가 아직 남아있다.
attention mechanism을 통해 위에서 언급했던 RNN 모델의 문제점을 어느정도 해결했지만 결국 대부분의 모델은 attention이 RNN과 함께 사용되는 용도로만 사용되었다.
해당 논문에서는 Transformer 라 불리는 모델을 소개한다. 다른 CNN 혹은 RNN 모델 없이 단순히 attention mechanism만으로 모델을 구성했으며 학습시간이 매우 빠르다는 장점이 있다.
Model Architecture
대부분의 sequence를 다루는 모델들은 encoder-decoder 구조로 되어있다. 여기서 encoder는 input sequence를 continuous한 representations로 바꾸고 decoder는 이 representation을 통해 output을 만들어낸다.
Transformer의 전체적인 architecture는 stacked self-attention(intra-attention)과 point-wise fc layer들을 사용해서 구성되어 있다. 아래 그림이 전체 architecture를 나타낸다. 그림에서 왼쪽이 encoder이고 오른쪽이 decoder이다.
이제 모델 하나하나 자세히 알아보도록 하자.
Encoder & Decoder
Encoder
Encoder는 동일한 layer가 N개 반복되는 형태이다. 이 논문에서는 6번 반복했다. 그리고 각 layer는 두개의 sub-layer로 구성된다. 첫 sub-layer는 multi-head self-attention mechanism이고 두번쨰는 간단한 point-wise fc-layer이다. 그리고 모델 전체적으로 각 sub-layer에 residual connection을 사용했다. 그리고 residual 값을 더한 뒤에 layer 값을 Nomalize한다. 즉 각 sub-layer는 결과에 대해 residual 값을 더하고 그 값을 nomalize한 값이 output으로 나오게 된다. 그리고 모델 전체적으로 residual 계산을 쉽게하기 위해서 output의 dimension은 모두 512로 맞췄다.
Decoder
Decoder도 encoder와 마찬가지로 동일한 layer가 N개 반복되는 형태이다. 그리고 이 논문에서는 decoder도 6번 반복했다. 그러나 반복되는 layer가 encoder와는 다른 구조이다. 총 3개의 sub-layer로 구성되어 있는데, 2개는 기존의 encoder의 sub-layer와 동일하고 나머지 하나는 encoder의 ouput에 대해 multi-head attention을 계산하는 sub-layer가 추가되었다. 그림으로 보면 오른쪽의 가운데 sub-layer이다.
Decoder에서도 residual connection을 사용했다. residual 값을 더한 후 동일하게 layer nomalize를 해준다. 그리고 self-attetion을 encoder와는 약간 다르게 수정을 했는데, masking을 추가했다. self-attention시 현재 위치보다 뒤에 있는 단어는 attend 못하도록 masking을 추가해준 것이다.
Attention
이 모델에서 사용한 attention은 총 2가지 종류이다. 하나는 Scaled dot-product attention이고 나머지 하나는 Multi-head attention이다.
Scaled dot-product attention
해당 attention의 input은 3가지다. $d_k$ dimension을 가지는 queries와 keys, 그리고 $d_v$ dimension을 가지는 values로 구성된다. 우선 하나의 query에 대해 모든 key들과 dot product를 한 뒤 각 값을 로 나눠준다. 그리고 softmax함수를 씌운 후 마지막으로 value를 곱하면 attention 연산이 끝난다.
실제로 계산할때는 query, key, value를 vector하나하나 계산하는 것이 아니라 여러개를 matrix로 만들어 계산한다. 수식은 다음과 같다.
추가적인 설명 우선 query와 key, value에 대해서 설명하면 query가 어떤 단어와 관련되어 있는지 찾기 위해서 모든 key들과 연산한다. 여기서 실제 연산을 보면 query와 key를 dot-product한뒤 softmax를 취하는데, 의미하는 것은 하나의 query가 모든 key들과 연관성을 계산한뒤 그 값들을 확률 값으로 만들어 주는 것이다. 따라서 query가 어떤 key와 높은 확률로 연관성을 가지는지 알게 되는 것이다. 이제 구한 확률값을 value에 곱해서 value에 대해 scaling한다고 생각하면된다.
추가적인 설명 key와 value는 사실상 같은 단어를 의미한다. 하지만 두개로 나눈 이유는 key값을 위한 vector와 value를 위한 vector를 따로 만들어서 사용한다. key를 통해서는 각 단어와 연관성의 확률을 계산하고 value는 그 확률을 사용해서 attention 값을 계산하는 용도이다.
보통 흔히 사용되는 attention 함수는 additive attention과 dot-product(multiplicative) attention 두가지다. 후자의 경우가 현재 사용하고 있는 attention과 거의 유사하다. 다른점은 $\frac{1}{\sqrt{d_k}}$로 scailing을 하지 않았다는 점이다. 그리고 dot-product attention과 additive attention을 비교하면 dot-product attention이 속도측면에서 앞선다. 복잡도는 비슷한데 속도가 앞서는 이유는 matrix multiplication에 대한 최적화된 구현이 많이 있기 때문이다.
그리고 앞서 설명하지 않았던 것이 하나 있다. rescaling을 하는 부분인데, 만약 dimension의 루트값으로 나눠주지 않는다면 어떤 일이 생기는지 생각해보자. vector의 길이가 길어질수록, 즉 dimension이 커질수록 자연스럽게 dot-product값은 점점 더 커질 것이다. 그러나 이후에 softmax함수가 있기 때문에 back-propagation 과정에서도 미분값이 조금만 넘어오게 되서 상대적으로 학습이 느려지거나 학습이 잘안되는 상황이 발생할 수 있다. 따라서 dimension이 큰 경우를 대비해 dimension의 루트값으로 나눠준다.
Multi-head attention
기존의 attention은 전체 dimension에 대해서 하나의 attention만 적용시켰다. 여기서 사용한 Multi-head attention이란 전체 dimension에 대해서 한번 attention을 적용하는 것이 아니라 전체 dimension을 h로 나눠서 attention을 $h$번 적용시키는 방법이다.
각 query, key, value의 vector는 linearly하게 $h$개로 project 된다. 이후 각각 나눠서 attention을 시킨 후 만들어진 $h$개의 vector를 concat하면 된다. 마지막으로 vector의 dimension을 로 다시 맞춰주도록 matrix를 곱하면 끝난다. Multi-head attention을 수식으로 표현하면 다음과 같다.
각 파라미터의 shape은 다음과 같다.
해당 논문에서는 $h=8$ 즉 8개의 head를 사용했다. 따라서 각 vector들의 dimension은 다음과 같이 8로 나눠진다.
$h$번 계산했지만 각 head들이 dimension이 줄었기 때문에 전체 연산량은 비슷하다.
Applications of Attention in our Model
Transformer에서 multi-head attention을 다음과 같은 방법으로 사용했다.
- “encoder-decoder attention” layer에서 query들은 이전 decoder layer에서 온다. 그리고 encoder에서 온 key와 value를 사용한다. 따라서 decoder의 모든 위치의 token은 input sequence의 어느 곳이든 attend할 수 있게 된다.
- encoder는 self-attention layer를 가진다. 모든 key, value, query는 같은 sequence에서 온다. 정확히는 이전 layer의 output에서 온다. 따라서 encoder는 이전 layer의 전체 위치를 attend할 수 있다.
- decoder의 self-attention layer도 이전 layer의 모든 position을 attend 할 수 있는데, 정확히는 자신의 position이전의 position까지만 attend 할 수 있다. 직관적으로 이해하면 sequence에서 앞의 정보만을 참고할 수 있게 한 것이다. 이러한 목적을 scaled dot-product를 masking 함으로써 구현했다.
Position-wise Feed-Forward Networks
attention sub-layer에 이어서 fully connected feed-forward network 거치게 되는데 이 network는 두개의 linear transformation으로 구성되어 있고 두 transformation 사이에 ReLU 함수를 사용한다.
Embeddings and Softmax
다른 sequence 모델과 유사하게 embedding vector를 사용한다. 입력 token을 linear transformation 해서 dimension vector로 바꿔주고 softmax로 나온 decoder의 결과 값을 predicted next-token으로 다시 linear transformation해서 바꿔준다. 모델 전체를 보면 3번 embedding 과정(역 embedding 포함)이 있는데, 이 때 linear transofrmation에 사용되는 weight matrix는 다 같은 matrix를 사용한다. 즉 2개의 embedding layer에서의 linear transformation과 softmax 다음의 linear transormation에서 같은 matrix를 사용하는 것이다.
Positional Encoding
해당 모델에서는 recurrence나 convolution을 전혀 사용하지 않았기 떄문에, 추가적으로 위치 정보를 넣어줘야 한다. 따라서 “positional encoding”을 사용해서 input embedding에 위치 정보를 넣어준다. 각 위치에 대해서 embedding과 동일한 dimension을 가지도록 encoding을 해준 뒤 그 값을 embedding값과 더해서 사용한다.
positional encoding에는 여러 방법이 있지만 여기서는 sin, cos 함수를 사용해서 구현한다. 각 위치 $pos$와 dimension $i$에 대한 positional encoding값은 다음과 같이 구한다.
Why self-attention
이 모델에서 recurrent 나 convolution을 사용하지 않고 self-attention만을 사용한 이유에 대해서 알아보자. 3가지 이유로 self-attention을 선택했다.
- 레이어당 전체 연산량이 줄어든다.
- 병렬화가 가능한 연산이 늘어난다.
- long-range의 term들의 dependency도 잘 학습할 수 있게 된다.
그리고 위의 3가지 외에 또 다른 이유는 attention을 사용하면 모델 자체의 동작을 해석하기 쉬워진다는(interpretable) 장점 때문이다. attention 하나의 동작 뿐만 아니라 multi-head의 동작 또한 어떻게 동작하는지 이해하기 쉽다는 장점이 있다. 아래의 그림을 보면 어떻게 attention mechanism이 적용되는지 쉽게 이해할 수 있다.
Training
학습에 사용된 것들을 하나씩 알아보자.
Training data and batching
학습에 사용된 데이터는 WMT 2014 English-German 데이터 셋이다. 총 450만개의 영어-독일어 문장 쌍이 있다. 그리고 WMT 2014 English-French 데이터 셋도 사용했다. 총 360만개의 문장 쌍이 있다. 학습시 대략 25000개의 token을 포함하는 문장 쌍을 하나의 배치로 사용했다.
Optimizer
학습에 사용된 optimizer는 Adam을 사용했다. 하이퍼 파라미터로는 $\beta_1=0.9$, $\beta_2=0.98$, $\epsilon=10^{-9}$를 사용했다. 학습률(learning rate)의 경우 학습 경과에 따라서 변화하도록 만들었다. 아래의 공식으로 학습률을 계산해서 적용했다.
여기서 warmup_step의 값으로는 4000을 사용했다.
Regularization
학습 시 정규화를 위해서는 세가지 방법을 사용했다.
- Residual dropout
- Attention dropout
- label smoothing
여기서 dropout 값은 0.1로 했고, label smoothing 값도 0.1로 설정했다.
Conclusion
번역에서 Tansformer는 다른 모델들 보다 훨씬 빠르게 학습했다. 그리고 빠른 속도에도 성능에서도 이전의 모델들보다 좋은 성능을 보여줬다.
Recurrent, convolution을 전혀 사용하지 않고 attention만 사용해서 만든 모델임에도 좋은 성능을 보여줬다. 우선 이 모델이 크게 의미하는 바는 빠른 학습속도를 보여준 것이다. 따라서 앞으로도 번역 뿐만 아니라 이미지 등 큰 input을 가지는 문제에도 적용할 수 있을 것이다.
오역 및 잘못된 내용이 있을 수 있습니다. 잘못된 부분 혹은 이해가 잘 안되는 부분은 댓글 혹은 메일로 말씀해주시면 감사하겠습니다!
Comments