
Word2Vec (1) : 단어 임베딩 & CBOW 모델
21 Jul 2018 | NLP
Word2Vec
NLP에 처음 공부하고 부터 계속해서 듣고 사용하는 기술 중 하나는 무엇보다도 Word2Vec이다. 기존의 one-hot vector 방식의 단어 표현은 단어간 유사도를 전혀 표현할 수 없다는 치명적인 단점을 해결하기 위해 Google에서 나온 기술로 단어들의 특정 dimension의 vector로 만들어 주는 word embedding의 대표적인 방법이다.
매번 라이브러리를 사용해 Word2Vec을 사용만해와서 학습과정이나 모델의 세부적인 내용에 대해서는 잘 알지 못했는데 cs224n 강의를 들으면서 이번 기회에 정리를 해보려한다.
다음의 순서로 Word2Vec을 소개하려한다.
- Word Embedding & Word2Vec(CBOW model)
- Word2Vec(Skip-Gram) & 튜닝 기법(다음 포스트)
WordEmbedding
컴퓨가 문장을 어떻게 이해할까? 컴퓨터의 경우 문자를 유니코드의 집합으로 읽을 것이다. 따라서 컴퓨터가 문장의 뜻이나 문장간의 유사도등을 이해하기는 불가능에 가까울 것이다. 그래서 컴퓨터에게 문장을 학습시키위해 단어를 수치화시키는 것이 첫 목표였다.
가장 기존의 방식은 다음과 같다. 다음과 같은 단어가 있다고 하자.
그리고 우리는 여러 단어를 포함하는 다음과 같은 사전을 가지고 있다.
그렇다면 위의 문장은 다음의 벡터들의 집합으로 표현할 수 있다.
이런 방법을 one-hot encoding 방법이라 부른다. 벡터의 하나의 원소만 ‘1’이고 나머지는 모두 ‘0’인 벡터로 encoding한다는 것이다. 하지만 이러한 방법들은 단어를 수치화하는데는 성공했지만 치명적인 단점이 있다.
- 단어간 유사도를 나타낼 수 없다.(어느 두벡터를 내적해서 0이나온다)
- 문장 데이터가 많아질수록 사전벡터의 크기가 너무 커져 모델이 느려지고 비효율적이다.
- 벡터가 너무 크고 sparse하다.
이러한 문제를 해결하기 위해 단어를 유의미한 수치를 가지는 벡터로 만들기 위한 방법을 연구했다. 이러한 방법을 Word Embedding이라 부른다. 따라서 단어는 각 벡터로 표현되고 이 벡터는 단어들간 유사도 또한 나타내는 것이다.
이러한 방법은 2003년부터 제기된 방법부터 여러가지가 있지만 최근 가장많이 사용하고 가장 효율이 좋은 Miklov에 의해 만들어진 word2vec에 대해 알아보도록 한다.
Word2Vec
Word2Vec은 2013년 Efficient Estimation of Word Representations in
Vector Space에서 처음 나왔으며, 이후 같은 모델이지만 몇 가지 튜닝기법 추가와 약간 수정된 Distributed Representations of Words and Phrases
and their Compositionality
이 나왔다.
Word2Vec의 가장 중요한 아이디어는 언어학의 Distributional Hypothesis이다. 즉 ‘비슷한 분포를 가진 단어들은 비슷한 의미를 가진다’라는 의미로 좀 더 쉽게 표현하면 같이 등장하는 횟수가 많을 수록 두 단어는 비슷한 의미를 가진다 라는 내용이 핵심 아이디어이다.
모델은 Continuous Bag Of Word(CBOW)와 Skip-Gram모델 두 가지다. 최근에는 CBOW보다는 Skip-Gram을 주로 사용하지만, 여기서는 두 모델 모두 하나씩 알아보도록 하자.
Continuous Bag of Words Model (CBOW)
CBOW의 기본적인 아이디어는 다음과 같다.
주변단어를 통해서 주어진 단어가 무었인지 찾는 것이다. 정확히는 앞뒤로 $\frac c2$개의 단어를 (총c개) 통해 주어진 단어를 예측한다는 것이 CBOW의 아이디어이다.
다음의 문장을 보자
“아침을 안먹었더니 __가 너무 고프다”
위와같은 문장이 있다고 하자. 우리는 주변 단어들을 통해 빈칸에 들어갈 단어를 예측할 수 있다.
CBOW의 아키텍처는 다음의 그림과 같다.
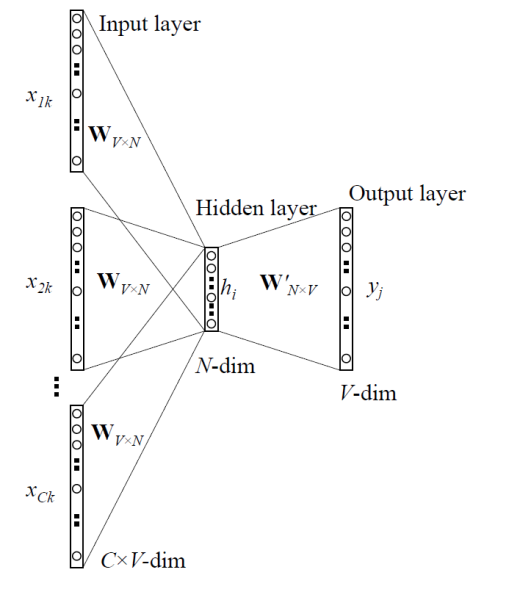 CBOW의 학습과정에 대해 알아보자.
CBOW의 학습과정에 대해 알아보자.
우선 학습시킬 문장의 모든 단어들을 one-hot encoding 방식으로 벡터화 한다.
그리고 하나의 중심단어에 대해 $2m$개의 단어 벡터를 input값으로 갖는다.
파라미터는 Input Layer에서 Hidden Layer로 가는 파라미터 매트릭스와 output layer로 가는 파라미터 매트릭스 이다.
(작성상 편의와 햇갈림을 방지하기 위해 $\mathbf{W}^{\prime}$는 아래의 설명에서는 $\mathbf{U}$작성했다.)
이 모델의 목적은 주변단어들이 주어졌을 떄의 중심 단어의 조건부 확률을 최대화 하는 것이다. 즉 다음의 확률을 최대화 하는 것이다.
그렇다면 네트워크의 진행 과정에 대해서 알아보자.
각 단어는 one-hot encoding 방식이므로 파라미터 $W$와 곱하면 각 단어를 나타내는 행과 곱해지고 나머지는 0으로 곱해지지 않을 것이다. 아래의 그림을 보면 명확하게 이해될 것이다.

즉 one-hot encoding 방식의 단어벡터들은 파라미터와 곱해져서 embedded word vector가 될 것이다.
이후 $2m$개의 embedded vector들의 평균을 구한다. 이때 평균해서 구한 벡터가 Hidden Layer값이 된다.
이제 output layer로 전달할 값인 score값을 계산해야 한다. 파라미터 $\mathbf{U}$를 곱해서 각 단어에 대한 score를 만든다. 가까운 위치의 단어들은 높은 값을 갖도록 해야 한다.
마지막으로 각 score값들을 확률 값으로 계산한다.
확률은 softmax를 사용한다. 각 단어에 파라미터 $\mathbf{W}$를 곱하면 단어는 one-hot vector이기 때문에 각 단어에 해당하는 행만 계산될 것이다. 이때 각 단어에 해당하는 행은 단어의 embedding vector($v_k$)가 된다.
네트워크의 진행과정에 대해서 소개했다. 이제 필요한 것은 이 파라미터들을 학습하는 것이다. 학습을 위해 Objective function을 정의해야한다. Objective function은 아래와 같으며 우리는 그 값을 minimize하는 방향으로 학습할 것이다.
Objective function은 위와 같다. 모든 원소에 대한 sum을 계산하는 것이지만 $y_j$벡터가 one-hot vector라는 것을 기억하자. 결국 하나의 원소에 대해서만 계산될 것이다. 결국 Objective function은 다음과 같이 간단하게 표현할 수 있다.
여기서 $i$는 우리가 예측하는 단어가 될 것이다.
단어를 정확하게 예측했다면 $H$값은 0이 될 것이다.그리고 우리는 위 식을 다음과 같이 확률 분포에 대한 식으로 볼 수 있다. 따라서 Objective funciton을 다음과 같이 표현한다.
optimize 방법으로는 SGD를 사용한다.
마지막으로 CBOW모델의 계산량은 다음과 같다.
- $C$개의 단어를 Hidden Layer로 보내는 $C\times N$
- Hidden Layer에서 Output Layer로 가는 $N\times V$
즉 전체 계산량은 $C\times N + N\times V$이다.
모든 문장에 대해 학습을 마친후 우리는 $W$ 행렬의 각 행을 각 단어의 embedding vector로 사용하게 된다.
Word2Vec
NLP에 처음 공부하고 부터 계속해서 듣고 사용하는 기술 중 하나는 무엇보다도 Word2Vec이다. 기존의 one-hot vector 방식의 단어 표현은 단어간 유사도를 전혀 표현할 수 없다는 치명적인 단점을 해결하기 위해 Google에서 나온 기술로 단어들의 특정 dimension의 vector로 만들어 주는 word embedding의 대표적인 방법이다.
매번 라이브러리를 사용해 Word2Vec을 사용만해와서 학습과정이나 모델의 세부적인 내용에 대해서는 잘 알지 못했는데 cs224n 강의를 들으면서 이번 기회에 정리를 해보려한다.
다음의 순서로 Word2Vec을 소개하려한다.
- Word Embedding & Word2Vec(CBOW model)
- Word2Vec(Skip-Gram) & 튜닝 기법(다음 포스트)
WordEmbedding
컴퓨가 문장을 어떻게 이해할까? 컴퓨터의 경우 문자를 유니코드의 집합으로 읽을 것이다. 따라서 컴퓨터가 문장의 뜻이나 문장간의 유사도등을 이해하기는 불가능에 가까울 것이다. 그래서 컴퓨터에게 문장을 학습시키위해 단어를 수치화시키는 것이 첫 목표였다. 가장 기존의 방식은 다음과 같다. 다음과 같은 단어가 있다고 하자.
그리고 우리는 여러 단어를 포함하는 다음과 같은 사전을 가지고 있다.
그렇다면 위의 문장은 다음의 벡터들의 집합으로 표현할 수 있다.
이런 방법을 one-hot encoding 방법이라 부른다. 벡터의 하나의 원소만 ‘1’이고 나머지는 모두 ‘0’인 벡터로 encoding한다는 것이다. 하지만 이러한 방법들은 단어를 수치화하는데는 성공했지만 치명적인 단점이 있다.
- 단어간 유사도를 나타낼 수 없다.(어느 두벡터를 내적해서 0이나온다)
- 문장 데이터가 많아질수록 사전벡터의 크기가 너무 커져 모델이 느려지고 비효율적이다.
- 벡터가 너무 크고 sparse하다.
이러한 문제를 해결하기 위해 단어를 유의미한 수치를 가지는 벡터로 만들기 위한 방법을 연구했다. 이러한 방법을 Word Embedding이라 부른다. 따라서 단어는 각 벡터로 표현되고 이 벡터는 단어들간 유사도 또한 나타내는 것이다.
이러한 방법은 2003년부터 제기된 방법부터 여러가지가 있지만 최근 가장많이 사용하고 가장 효율이 좋은 Miklov에 의해 만들어진 word2vec에 대해 알아보도록 한다.
Word2Vec
Word2Vec은 2013년 Efficient Estimation of Word Representations in Vector Space에서 처음 나왔으며, 이후 같은 모델이지만 몇 가지 튜닝기법 추가와 약간 수정된 Distributed Representations of Words and Phrases and their Compositionality 이 나왔다.
Word2Vec의 가장 중요한 아이디어는 언어학의 Distributional Hypothesis이다. 즉 ‘비슷한 분포를 가진 단어들은 비슷한 의미를 가진다’라는 의미로 좀 더 쉽게 표현하면 같이 등장하는 횟수가 많을 수록 두 단어는 비슷한 의미를 가진다 라는 내용이 핵심 아이디어이다. 모델은 Continuous Bag Of Word(CBOW)와 Skip-Gram모델 두 가지다. 최근에는 CBOW보다는 Skip-Gram을 주로 사용하지만, 여기서는 두 모델 모두 하나씩 알아보도록 하자.
Continuous Bag of Words Model (CBOW)
CBOW의 기본적인 아이디어는 다음과 같다. 주변단어를 통해서 주어진 단어가 무었인지 찾는 것이다. 정확히는 앞뒤로 $\frac c2$개의 단어를 (총c개) 통해 주어진 단어를 예측한다는 것이 CBOW의 아이디어이다. 다음의 문장을 보자
“아침을 안먹었더니 __가 너무 고프다”
위와같은 문장이 있다고 하자. 우리는 주변 단어들을 통해 빈칸에 들어갈 단어를 예측할 수 있다.
CBOW의 아키텍처는 다음의 그림과 같다.
CBOW의 학습과정에 대해 알아보자.
우선 학습시킬 문장의 모든 단어들을 one-hot encoding 방식으로 벡터화 한다.
그리고 하나의 중심단어에 대해 $2m$개의 단어 벡터를 input값으로 갖는다.
파라미터는 Input Layer에서 Hidden Layer로 가는 파라미터 매트릭스와 output layer로 가는 파라미터 매트릭스 이다.
(작성상 편의와 햇갈림을 방지하기 위해 $\mathbf{W}^{\prime}$는 아래의 설명에서는 $\mathbf{U}$작성했다.)
이 모델의 목적은 주변단어들이 주어졌을 떄의 중심 단어의 조건부 확률을 최대화 하는 것이다. 즉 다음의 확률을 최대화 하는 것이다.
그렇다면 네트워크의 진행 과정에 대해서 알아보자. 각 단어는 one-hot encoding 방식이므로 파라미터 $W$와 곱하면 각 단어를 나타내는 행과 곱해지고 나머지는 0으로 곱해지지 않을 것이다. 아래의 그림을 보면 명확하게 이해될 것이다.
즉 one-hot encoding 방식의 단어벡터들은 파라미터와 곱해져서 embedded word vector가 될 것이다.
이후 $2m$개의 embedded vector들의 평균을 구한다. 이때 평균해서 구한 벡터가 Hidden Layer값이 된다.
이제 output layer로 전달할 값인 score값을 계산해야 한다. 파라미터 $\mathbf{U}$를 곱해서 각 단어에 대한 score를 만든다. 가까운 위치의 단어들은 높은 값을 갖도록 해야 한다.
마지막으로 각 score값들을 확률 값으로 계산한다.
확률은 softmax를 사용한다. 각 단어에 파라미터 $\mathbf{W}$를 곱하면 단어는 one-hot vector이기 때문에 각 단어에 해당하는 행만 계산될 것이다. 이때 각 단어에 해당하는 행은 단어의 embedding vector($v_k$)가 된다.
네트워크의 진행과정에 대해서 소개했다. 이제 필요한 것은 이 파라미터들을 학습하는 것이다. 학습을 위해 Objective function을 정의해야한다. Objective function은 아래와 같으며 우리는 그 값을 minimize하는 방향으로 학습할 것이다.
Objective function은 위와 같다. 모든 원소에 대한 sum을 계산하는 것이지만 $y_j$벡터가 one-hot vector라는 것을 기억하자. 결국 하나의 원소에 대해서만 계산될 것이다. 결국 Objective function은 다음과 같이 간단하게 표현할 수 있다.
여기서 $i$는 우리가 예측하는 단어가 될 것이다. 단어를 정확하게 예측했다면 $H$값은 0이 될 것이다.그리고 우리는 위 식을 다음과 같이 확률 분포에 대한 식으로 볼 수 있다. 따라서 Objective funciton을 다음과 같이 표현한다.
optimize 방법으로는 SGD를 사용한다. 마지막으로 CBOW모델의 계산량은 다음과 같다.
- $C$개의 단어를 Hidden Layer로 보내는 $C\times N$
- Hidden Layer에서 Output Layer로 가는 $N\times V$
즉 전체 계산량은 $C\times N + N\times V$이다.
모든 문장에 대해 학습을 마친후 우리는 $W$ 행렬의 각 행을 각 단어의 embedding vector로 사용하게 된다.
Comments