
Memory Network
05 Oct 2018 | NLP
이번에 리뷰할 논문은 Memory Network입니다. Memory network 중 첫 논문으로 이 모델에서 중점적으로 보는 부분은 memory를 사용해서 긴 text에서 필요한 부분만 저장해서 사용할 수 있도록 하는 것입니다. 주로 Question Answering Task에 실험했으며, QA task를 여러 경우로 나눠서 모델을 구성했습니다. 이 모델의 경우 QA 분야가 아니라 Text generation 등 다른 분야에서 사용할 수 있으며 넓은 범위로 의미있는 논문이므로 자세히 리뷰를 통해 자세히 알아보겠습니다. 해당 Post 이후 향후 이 논문 이후에 나온 “End-to-End Memory Network” 까지 알아봄으로써 Memory Network에 대해 자세히 다룰 예정입니다.
Introduction
대부분의 머신러닝 모델은 long-term component를 잘 읽고 사용하지 못한다. 예를 들면 전체 소설을 읽고 주제를 말하는 것과 같은 질문을 답하기는 어렵다. RNN 모델을 사용하면서 이런 long-term을 잘 읽을 수 있게 되긴 했지만, 결국 이 memory가 hidden state vector & weights 로 저장되는데, 크기 자체가 크지않고 제한적이다.
따라서 여기서는 momory network라 불리는 모델을 통해 이러한 문제를 해결하고자 한다. 핵심 idea는 머신러닝에서 효과적인 학습 전략과 memory component를 결합해서 사용하는 것이다. 이제 모델에 대해서 알아보자.
Memory Network
Memory Network는 메모리 $\mathbf{m}$(객체 $\mathbf{m}_i$ 들의 배열, 여기서 말하는 객체는 vector 혹은 string을 뜻한다)와 4개의 component인 $I,G,O,R$로 구성된다. 여기서 말하는 4개의 component의 역할은 다음과 같다.
- $I$: (input feature map) input을 내부적인 feature 표현으로 바꿔준다.
- $G$: (generalization) 새로운 인풋을 통해 기존의 memory를 update한다. 이러한 과정을 genralization이라 부른다.
- $O$: (output feature map) 새로운 input과 현재 memory의 값들을 사용해 output을 만든다.
- $R$: (response) output을 원하는 포맷의 response로 만들어 준다. 예를 들면 터를 text 혹은 action 으로 바꿔준다.
위의 4가지 component에 대한 설명은 범용적인 개념으로 설명되어 있다. 따라서 해당 모델이 사용한 것에 맞게 component들을 설명하면 다음과 같다.
- $I$: input 값을 bag-of-word를 사용해서 embedding 해준다.
- $G$: embedding 한 vector를 남아있는 memory slot $m_n$ 에 저장한다. 이 경우에 기존것이 삭제 될 수 있다.
- $O$: 모든 memory 값에 대해서 k번 loop를 돌며 match되는 값을 찾고 최종적으로 output $o$를 만들어낸다. (아래 loop은 k=2 인 경우)
- 1st - input 값과 가장 match score가 높은 memory slot $m_i$를 찾는다.
- 2nd - input 과 이전 loop에서 찾은 memory slot $m_i$를 같이 사용해 다음으로 match score가 높은 memory slot인 $m_j$를 찾는다.
- input과 $m_i,~m_j$ 모두 사용해 output 값을 만든다.
- $R$: (reponse) output을 사용해 dictionary의 모든 word들의 score를 계산해 하나의 word를 찾는다.
즉 전체 모델은 memory와 4개의 component들을 사용하는 구조이다. 모델의 전체적인 그림은 다음과 같다.
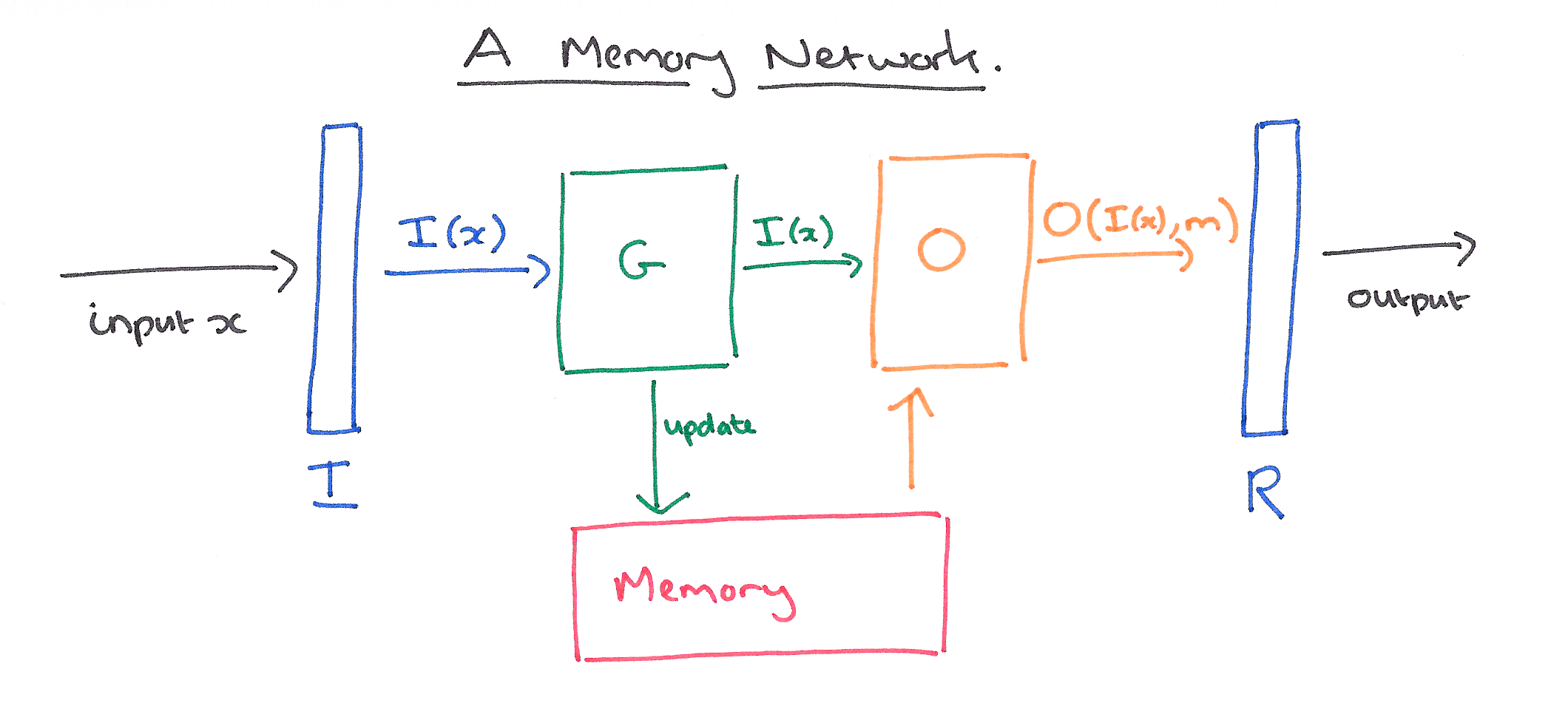
이제 모델에 대해 자세히 알아보자. 모델은 input $x$가 다음의 순서로 모델에 흘러간다. 여기서 input 값은 charcter, word, sentence등이 될 수 있다.(image or audio signal이 될 수도 있다)
- input $x$를 feature 표현으로 바꾼다. 즉 embedding한다: $I(x)$.
- 새로운 input으로 memory를 update한다: $\mathbf{m}_i=G(\mathbf{m}_i,I(x),\mathbf{m}), \forall i$.
- input과 memory를 이용해 output $o$를 계산한다: $o=O(I(x),\mathbf{m})$
- 마지막으로 output을 decode해서 최종 response를 만든다: $r=R(o)$
위의 process는 학습과 테스트 모두에 적용된다. 학습과 테스트의 다른점은 학습시에는 memory와 4개의 component인 $I,G,O,R$모두 update되는데 테스트 때는 memory만 update된다.
그리고 memory netword의 해당 모델은 범용적으로 제안된 모델로 각각의 component들은 기존의 machine model 어느 것을 사용해서 구현할 수 있다.(e.g SVMs, decision tress, etc.)
이제 각 component들 각각에 대해서 자세히 살펴보자.
$I$ - component
$I$ component는 전처리의 표준으로 사용할 수 있다. 예를 들면 text input을 parsing, coreference, entity resolution 등을 하는 과정을 넣을 수 있다. 이러한 과정을 통해 raw한 input값을 feature 표현(representation)으로 만든다. 즉 text 를 feature vector로 만들어 준다.
$G$ - component
component $G$의 가장 간단한 형태는 $I(x)$를 memory의 “slot”에 저장하는 것이다. 즉 아래의 식을 수행하는 것이 component $G$가 된다.
여기서 $H(.)$는 저장될 slot을 선택하는 함수이다. 즉 $G$는 memory의 배열 중 index $H(x)$의 메모리인 $\mathbf{m}_{H(x)}$를 update한다. $G$는 구현 방법에 따라 기존에 slot에 저장된 memory를 모두 제거하거나 부분적으로 제거한 후 update한다.
그리고 만약 memory가 커질 경우에는 memory를 조직화할 필요가 있다. 이 때 Hash 함수를 사용해 choosing 함수인 $H(x)$를 구현한다. 그리고 이 함수는 경우에 따라 주제나 개체에 따라 저장되는 곳이 함수를 통해 지정될 수 있다. 즉 choosing 을 모든 slot에 대해서 적용하는 것이 아니라, 조직화한 후 적용되는 부분 slot에 대해서만 choosing한다.
그리고 만약 메모리가 가득 찼다면 “foregetting”이라는 $H$를 통해 구현해야 한다. 즉 $H$는 각 메모리의 사용에 대한 점수를 측정하고 점수가 낮은 memory를 제거한 후 update한다. 이런 forgetting에 대한 부분은 이 논문에서 구현하고 실험하지 않았다.
$O$ and $R$ components
$O$ component는 memory를 읽고 inference 과정을 수행한다. 예를 들어 연관성이 높은 memory와 계산하고 output을 만들어낸다. 그리고 $R$ component는 output으로 부터 최종 결과물을 만들어 낸다. Question answering 분야로 생각해보면, $O$를 통해 연관성 높은 memory 와 계산을 해서 output을 만들고 $R$을 통해 해당 output을 다시 실제 답변 text로 만들어 낸다.
A MenNN Implementation for Text
Memory Network 구현의 하나의 예시로 각 components를 Nerual network로 구현했다. 따라서 이러한 모델을 memory neural networks(MenNNs)라 부르고, 이번 section에서 이러한 방법으로 구현한 모델에 대해서 설명한다. 그리고 이 모델의 input과 output은 text인 경우를 다룰 것이다.
Basic model
우선 기본적인 모델의 Architecture에 대해서 알아보자, $I$ 모듈은 text를 input으로 받는다. 여기서는 우선 text가 문장(sentence)라고 생각하자. 그리고 이 문장은 질문이 될수도 있고 사실들이 적혀있는 글일 수 있다. 그리고 text는 가능한 memory slot에 저장된다. 즉 $S(x)$를 통해서 비어있는 memory slot $N$을 찾고 해당 메모리에 input을 저장한다: $\mathbf{m}_N=x,~N=N+1$. $G$ 모듈은 새로운 메모리 저장에만 사용되고 이미 저장된 메모리는 건들지 않는다.
추론(inference)의 핵심은 $O$와 $R$ 모듈이다. $O$ 모듈은 input $x$에 대해 $k$개의 supporting memory를 찾는다. $k=2$로 예를 들어보자. 총 2번의 loop을 돌게되는데 첫 번째 loop에서는 input과 가장 match score가 높은 memory를 찾는다.
여기서 함수 $s_O$는 input 문장과 하나의 memory $\mathbf{m}_i$와의 match score를 측정한다. 그리고 이제 두 번째 loop에서는 input과 이전에 찾은 memory 를 같이 사용해 다음 match score가 높은 memory를 찾는다.
최종 output $o$는 가 된다. 그리고 이 값은 module $R$의 input으로 사용된다.
마지막으로 $R$ 모듈은 위의 input값을 사용해 text response인 $r$을 만든다. 가장 간단한 형태로 response를 만드는 방법은 $k$ loop을 돌며 나온 결과 중 마지막 memory인 $\mathbf{m}_{o_k}$를 text로 만드는 방법이다. 만약 sentence generation을 해야 된다면 하나의 예로 RNN모델을 사용해 generation 할 수 있다. 해당 논문에서의 실험에서는 text response를 단일 단어로 제한해서 모델을 만들었다. 이 경우에는 $O$의 output으로 나온 값들과 vocabulary $W$의 모든 단어들과의 score를 측정해서 가장 높은 score를 가지는 단어를 response로 출력한다. 즉 다음의 수식을 통해 $r$을 만든다.
예를 통해 모델을 이해해보자. 우선 아래의 문장을 input으로 사용한다고 하자.
Joe went to the kitchen. Fred went to the kitchen. Joe picked up the milk.
Joe travelled to the office. Joe left the milk. Joe went to the bath room
위 문장에 대해서 다음의 질문들이 주어진다고 하자.
Where is the milk now?
Where is Joe?
Where was Joe before the office?
우선 첫 번째 질문에 답한다고 하자. 그러면 input은 다음과 같다.
그리고 $O$ 모듈은 모든 메모리에 대해서 첫 번째 loop을 돌 것이다. 즉 전체 문장에 대해서 주어진 질문과 가장 유사한 문장을 찾아낸다. 그리고 이 경우에 결과를 통해 나온 memory는 다음과 같다.
그리고 그 다음 loop을 돌 것이다. 주어진 input 그리고 memory slot $\mathbf{m}_{o_1}$을 사용해서 다음으로 match score가 높은 두 번째 문장을 찾는다.
마지막으로 $R$ 모듈에서 $[x,\mathbf{m}{o_1},\mathbf{m}{o_2}]$를 사용해 최종 output을 만든다.
그리고 실험에서 score fucntion인 $s_O$와 $s_R$은 같은 형태의 함수를 사용했다.
여기서 $U$는 $n\times D$ matrix이다. $D$는 feature의 수를 뜻하고 $n$는 embedding 차원의 크기를 뜻한다. 그리고 $\Phi_x$ 와 $\Phi_y$ 는 raw한 형태의 text를 D 차원의 vector로 만들어주는 함수이다. $\Phi$ 함수의 가장 간단한 예는 bag of words 표현 방식을 사용하는 것이다. 이 실험에서 $D=3\vert W\vert$로 사용했다. 즉 각 문장을 3개의 표현방식을 사용해 vector로 만들었다. 하나는 $\Phi_x(.)$를 위한 representation이고, 하나는 $Phi_y$를 위한 representation이다. 그리고 마지막 하나는 이후의 장에서 설명한다. 이렇게 만든 이유는 input이 실제 처음 input text를 통해서 온 것인지, memory에서 온 것인지 구별하기 위해 각각 따로 representation을 했다. 마지막으로 $U$의 경우에도 $R$ 모듈과 $O$ 모듈 각각 다른 matrix를 사용했다.
Training
학습은 fully supervised setting을 통해 진행되었다. 즉 input과 response이 모두 주어지고 supporting sentence도 모두 labeling 되어있다. 따라서 score의 함수의 best choice를 알 수 있다. 그리고 학습 시 loss는 margin ranking loss함수를 사용하고 update는 stochastic gradient descent(SGD)를 사용했다. 우선 loss함수를 보면 다음과 같이 구성된다.
Loss 함수를 자세히 알아보자. 우선 3개의 부분으로 나눠지는데 이는 k를 설정함에 따라 달라진다. 이 경우에는 위와 같이 $k=2$의 경우이고, $k$ 값이 커질수록 loss의 term의 개수가 많아질 것이다. 우선 하나씩 알아보자. 첫 번째 term의 경우 첫 번째 memory 선정에 따른 loss이고, 두 번째는 두 번째 memory 선정에 따른 loss함수이다. 마지막은 최종 결과인 response의 loss함수가 된다. 각 loss함수는 동일하게 margin ranking loss함수 형태인데, 이 loss함수의 의미는 학습시 선택한 memory(혹은 response)인 과 선택하지 않은 것 중에서 score가 높은 memory(혹은 response)인 과의 차이가 margin(위 식에서는 $\gamma$)보다 크도록 학습시키는 과정이다. 예를 들어 생각해보자. 위 식에서 우리가 선택한 memory와의 score와 다른 선택지 중 가장 높은 score와의 차이가 margin인 $\gamma$보다 작다면 loss는 양수값이 나올 것이다. 만약 margin보다 큰 경우에는 max를 통해 loss값이 0이 된다.
그리고 MemNN 구현 시 R은 RNN을 사용해서 구현했다. 따라서 이 경우에는 loss 함수의 마지막 term을 일반적인 language modeling에서 사용되는 일반적인 log likelihood를 사용했다.
Word Sequences as Input
위에서는 input을 문장으로 가정한 모델을 설명했다. 만약에 input이 단어라면 어떻게 해야 할까? 우선 word로 들어올 경우 가장 큰 문제점은 statement와 question이 구분되지 않는다는 점이다. 따라서 위의 경우와는 다른 접근법이 필요하다. 따라서 “segementation” 함수, 즉 단어들을 구분지어서 statement와 question들을 구분시켜주는 학습시킬 함수를 사용한다. 이 함수를 segementer라 한다. 이 segementer을 사용하면 sequence를 memory에 쓸 수 있고 그 이후는 위에 나온 모델과 동일하게 사용하면된다. 그리고 이 segementer는 다른 component들과 같이 embedding model 형태이다.
여기서 $W_{seg}$는 vector이다. 이 vector의 역할은 embedding 된 값을 linear clasification 해주는 역할이다. 그리고 $c$는 input seqeunce로 vector 형태이다. 즉 각 단어들이 bag of words 형태로 들어온다. 따라서 이 함수의 결과값이 특정 margin $\gamma$보다 큰지 안큰지에 따라서 sequence가 하나의 segment인지 아닌지를 판단한다. 즉 아래와 같이 구분된다.
Result & Conclusion
실험결과에 대해서는 소개하지 않는다. 논문을 참고하길 바란다. 그리고 해당 모델은 하나의 Attention으로 볼 수 있는데, Hard attention으로 분류된다. 이후 다음 모델은 해당 모델보다 좀더 unsupervised한 성격의 모델로 Soft attention 성격의 모델이다. Memory를 사용하는 모델로 기존 RNN 혹은 LSTM 보다 성능이 좋다는 것을 확인할 수 있다.
오역 및 잘못된 내용이 있을 수 있습니다. 잘못된 부분 혹은 이해가 잘 안되는 부분은 댓글 혹은 메일로 말씀해주시면 감사하겠습니다!
이번에 리뷰할 논문은 Memory Network입니다. Memory network 중 첫 논문으로 이 모델에서 중점적으로 보는 부분은 memory를 사용해서 긴 text에서 필요한 부분만 저장해서 사용할 수 있도록 하는 것입니다. 주로 Question Answering Task에 실험했으며, QA task를 여러 경우로 나눠서 모델을 구성했습니다. 이 모델의 경우 QA 분야가 아니라 Text generation 등 다른 분야에서 사용할 수 있으며 넓은 범위로 의미있는 논문이므로 자세히 리뷰를 통해 자세히 알아보겠습니다. 해당 Post 이후 향후 이 논문 이후에 나온 “End-to-End Memory Network” 까지 알아봄으로써 Memory Network에 대해 자세히 다룰 예정입니다.
Introduction
대부분의 머신러닝 모델은 long-term component를 잘 읽고 사용하지 못한다. 예를 들면 전체 소설을 읽고 주제를 말하는 것과 같은 질문을 답하기는 어렵다. RNN 모델을 사용하면서 이런 long-term을 잘 읽을 수 있게 되긴 했지만, 결국 이 memory가 hidden state vector & weights 로 저장되는데, 크기 자체가 크지않고 제한적이다.
따라서 여기서는 momory network라 불리는 모델을 통해 이러한 문제를 해결하고자 한다. 핵심 idea는 머신러닝에서 효과적인 학습 전략과 memory component를 결합해서 사용하는 것이다. 이제 모델에 대해서 알아보자.
Memory Network
Memory Network는 메모리 $\mathbf{m}$(객체 $\mathbf{m}_i$ 들의 배열, 여기서 말하는 객체는 vector 혹은 string을 뜻한다)와 4개의 component인 $I,G,O,R$로 구성된다. 여기서 말하는 4개의 component의 역할은 다음과 같다.
- $I$: (input feature map) input을 내부적인 feature 표현으로 바꿔준다.
- $G$: (generalization) 새로운 인풋을 통해 기존의 memory를 update한다. 이러한 과정을 genralization이라 부른다.
- $O$: (output feature map) 새로운 input과 현재 memory의 값들을 사용해 output을 만든다.
- $R$: (response) output을 원하는 포맷의 response로 만들어 준다. 예를 들면 터를 text 혹은 action 으로 바꿔준다.
위의 4가지 component에 대한 설명은 범용적인 개념으로 설명되어 있다. 따라서 해당 모델이 사용한 것에 맞게 component들을 설명하면 다음과 같다.
- $I$: input 값을 bag-of-word를 사용해서 embedding 해준다.
- $G$: embedding 한 vector를 남아있는 memory slot $m_n$ 에 저장한다. 이 경우에 기존것이 삭제 될 수 있다.
- $O$: 모든 memory 값에 대해서 k번 loop를 돌며 match되는 값을 찾고 최종적으로 output $o$를 만들어낸다. (아래 loop은 k=2 인 경우)
- 1st - input 값과 가장 match score가 높은 memory slot $m_i$를 찾는다.
- 2nd - input 과 이전 loop에서 찾은 memory slot $m_i$를 같이 사용해 다음으로 match score가 높은 memory slot인 $m_j$를 찾는다.
- input과 $m_i,~m_j$ 모두 사용해 output 값을 만든다.
- $R$: (reponse) output을 사용해 dictionary의 모든 word들의 score를 계산해 하나의 word를 찾는다.
즉 전체 모델은 memory와 4개의 component들을 사용하는 구조이다. 모델의 전체적인 그림은 다음과 같다.
이제 모델에 대해 자세히 알아보자. 모델은 input $x$가 다음의 순서로 모델에 흘러간다. 여기서 input 값은 charcter, word, sentence등이 될 수 있다.(image or audio signal이 될 수도 있다)
- input $x$를 feature 표현으로 바꾼다. 즉 embedding한다: $I(x)$.
- 새로운 input으로 memory를 update한다: $\mathbf{m}_i=G(\mathbf{m}_i,I(x),\mathbf{m}), \forall i$.
- input과 memory를 이용해 output $o$를 계산한다: $o=O(I(x),\mathbf{m})$
- 마지막으로 output을 decode해서 최종 response를 만든다: $r=R(o)$
위의 process는 학습과 테스트 모두에 적용된다. 학습과 테스트의 다른점은 학습시에는 memory와 4개의 component인 $I,G,O,R$모두 update되는데 테스트 때는 memory만 update된다.
그리고 memory netword의 해당 모델은 범용적으로 제안된 모델로 각각의 component들은 기존의 machine model 어느 것을 사용해서 구현할 수 있다.(e.g SVMs, decision tress, etc.)
이제 각 component들 각각에 대해서 자세히 살펴보자.
$I$ - component
$I$ component는 전처리의 표준으로 사용할 수 있다. 예를 들면 text input을 parsing, coreference, entity resolution 등을 하는 과정을 넣을 수 있다. 이러한 과정을 통해 raw한 input값을 feature 표현(representation)으로 만든다. 즉 text 를 feature vector로 만들어 준다.
$G$ - component
component $G$의 가장 간단한 형태는 $I(x)$를 memory의 “slot”에 저장하는 것이다. 즉 아래의 식을 수행하는 것이 component $G$가 된다.
여기서 $H(.)$는 저장될 slot을 선택하는 함수이다. 즉 $G$는 memory의 배열 중 index $H(x)$의 메모리인 $\mathbf{m}_{H(x)}$를 update한다. $G$는 구현 방법에 따라 기존에 slot에 저장된 memory를 모두 제거하거나 부분적으로 제거한 후 update한다.
그리고 만약 memory가 커질 경우에는 memory를 조직화할 필요가 있다. 이 때 Hash 함수를 사용해 choosing 함수인 $H(x)$를 구현한다. 그리고 이 함수는 경우에 따라 주제나 개체에 따라 저장되는 곳이 함수를 통해 지정될 수 있다. 즉 choosing 을 모든 slot에 대해서 적용하는 것이 아니라, 조직화한 후 적용되는 부분 slot에 대해서만 choosing한다.
그리고 만약 메모리가 가득 찼다면 “foregetting”이라는 $H$를 통해 구현해야 한다. 즉 $H$는 각 메모리의 사용에 대한 점수를 측정하고 점수가 낮은 memory를 제거한 후 update한다. 이런 forgetting에 대한 부분은 이 논문에서 구현하고 실험하지 않았다.
$O$ and $R$ components
$O$ component는 memory를 읽고 inference 과정을 수행한다. 예를 들어 연관성이 높은 memory와 계산하고 output을 만들어낸다. 그리고 $R$ component는 output으로 부터 최종 결과물을 만들어 낸다. Question answering 분야로 생각해보면, $O$를 통해 연관성 높은 memory 와 계산을 해서 output을 만들고 $R$을 통해 해당 output을 다시 실제 답변 text로 만들어 낸다.
A MenNN Implementation for Text
Memory Network 구현의 하나의 예시로 각 components를 Nerual network로 구현했다. 따라서 이러한 모델을 memory neural networks(MenNNs)라 부르고, 이번 section에서 이러한 방법으로 구현한 모델에 대해서 설명한다. 그리고 이 모델의 input과 output은 text인 경우를 다룰 것이다.
Basic model
우선 기본적인 모델의 Architecture에 대해서 알아보자, $I$ 모듈은 text를 input으로 받는다. 여기서는 우선 text가 문장(sentence)라고 생각하자. 그리고 이 문장은 질문이 될수도 있고 사실들이 적혀있는 글일 수 있다. 그리고 text는 가능한 memory slot에 저장된다. 즉 $S(x)$를 통해서 비어있는 memory slot $N$을 찾고 해당 메모리에 input을 저장한다: $\mathbf{m}_N=x,~N=N+1$. $G$ 모듈은 새로운 메모리 저장에만 사용되고 이미 저장된 메모리는 건들지 않는다.
추론(inference)의 핵심은 $O$와 $R$ 모듈이다. $O$ 모듈은 input $x$에 대해 $k$개의 supporting memory를 찾는다. $k=2$로 예를 들어보자. 총 2번의 loop을 돌게되는데 첫 번째 loop에서는 input과 가장 match score가 높은 memory를 찾는다.
여기서 함수 $s_O$는 input 문장과 하나의 memory $\mathbf{m}_i$와의 match score를 측정한다. 그리고 이제 두 번째 loop에서는 input과 이전에 찾은 memory 를 같이 사용해 다음 match score가 높은 memory를 찾는다.
최종 output $o$는 가 된다. 그리고 이 값은 module $R$의 input으로 사용된다.
마지막으로 $R$ 모듈은 위의 input값을 사용해 text response인 $r$을 만든다. 가장 간단한 형태로 response를 만드는 방법은 $k$ loop을 돌며 나온 결과 중 마지막 memory인 $\mathbf{m}_{o_k}$를 text로 만드는 방법이다. 만약 sentence generation을 해야 된다면 하나의 예로 RNN모델을 사용해 generation 할 수 있다. 해당 논문에서의 실험에서는 text response를 단일 단어로 제한해서 모델을 만들었다. 이 경우에는 $O$의 output으로 나온 값들과 vocabulary $W$의 모든 단어들과의 score를 측정해서 가장 높은 score를 가지는 단어를 response로 출력한다. 즉 다음의 수식을 통해 $r$을 만든다.
예를 통해 모델을 이해해보자. 우선 아래의 문장을 input으로 사용한다고 하자.
Joe went to the kitchen. Fred went to the kitchen. Joe picked up the milk.
Joe travelled to the office. Joe left the milk. Joe went to the bath room
위 문장에 대해서 다음의 질문들이 주어진다고 하자.
Where is the milk now?
Where is Joe?
Where was Joe before the office?
우선 첫 번째 질문에 답한다고 하자. 그러면 input은 다음과 같다.
그리고 $O$ 모듈은 모든 메모리에 대해서 첫 번째 loop을 돌 것이다. 즉 전체 문장에 대해서 주어진 질문과 가장 유사한 문장을 찾아낸다. 그리고 이 경우에 결과를 통해 나온 memory는 다음과 같다.
그리고 그 다음 loop을 돌 것이다. 주어진 input 그리고 memory slot $\mathbf{m}_{o_1}$을 사용해서 다음으로 match score가 높은 두 번째 문장을 찾는다.
마지막으로 $R$ 모듈에서 $[x,\mathbf{m}{o_1},\mathbf{m}{o_2}]$를 사용해 최종 output을 만든다.
그리고 실험에서 score fucntion인 $s_O$와 $s_R$은 같은 형태의 함수를 사용했다.
여기서 $U$는 $n\times D$ matrix이다. $D$는 feature의 수를 뜻하고 $n$는 embedding 차원의 크기를 뜻한다. 그리고 $\Phi_x$ 와 $\Phi_y$ 는 raw한 형태의 text를 D 차원의 vector로 만들어주는 함수이다. $\Phi$ 함수의 가장 간단한 예는 bag of words 표현 방식을 사용하는 것이다. 이 실험에서 $D=3\vert W\vert$로 사용했다. 즉 각 문장을 3개의 표현방식을 사용해 vector로 만들었다. 하나는 $\Phi_x(.)$를 위한 representation이고, 하나는 $Phi_y$를 위한 representation이다. 그리고 마지막 하나는 이후의 장에서 설명한다. 이렇게 만든 이유는 input이 실제 처음 input text를 통해서 온 것인지, memory에서 온 것인지 구별하기 위해 각각 따로 representation을 했다. 마지막으로 $U$의 경우에도 $R$ 모듈과 $O$ 모듈 각각 다른 matrix를 사용했다.
Training
학습은 fully supervised setting을 통해 진행되었다. 즉 input과 response이 모두 주어지고 supporting sentence도 모두 labeling 되어있다. 따라서 score의 함수의 best choice를 알 수 있다. 그리고 학습 시 loss는 margin ranking loss함수를 사용하고 update는 stochastic gradient descent(SGD)를 사용했다. 우선 loss함수를 보면 다음과 같이 구성된다.
Loss 함수를 자세히 알아보자. 우선 3개의 부분으로 나눠지는데 이는 k를 설정함에 따라 달라진다. 이 경우에는 위와 같이 $k=2$의 경우이고, $k$ 값이 커질수록 loss의 term의 개수가 많아질 것이다. 우선 하나씩 알아보자. 첫 번째 term의 경우 첫 번째 memory 선정에 따른 loss이고, 두 번째는 두 번째 memory 선정에 따른 loss함수이다. 마지막은 최종 결과인 response의 loss함수가 된다. 각 loss함수는 동일하게 margin ranking loss함수 형태인데, 이 loss함수의 의미는 학습시 선택한 memory(혹은 response)인 과 선택하지 않은 것 중에서 score가 높은 memory(혹은 response)인 과의 차이가 margin(위 식에서는 $\gamma$)보다 크도록 학습시키는 과정이다. 예를 들어 생각해보자. 위 식에서 우리가 선택한 memory와의 score와 다른 선택지 중 가장 높은 score와의 차이가 margin인 $\gamma$보다 작다면 loss는 양수값이 나올 것이다. 만약 margin보다 큰 경우에는 max를 통해 loss값이 0이 된다.
그리고 MemNN 구현 시 R은 RNN을 사용해서 구현했다. 따라서 이 경우에는 loss 함수의 마지막 term을 일반적인 language modeling에서 사용되는 일반적인 log likelihood를 사용했다.
Word Sequences as Input
위에서는 input을 문장으로 가정한 모델을 설명했다. 만약에 input이 단어라면 어떻게 해야 할까? 우선 word로 들어올 경우 가장 큰 문제점은 statement와 question이 구분되지 않는다는 점이다. 따라서 위의 경우와는 다른 접근법이 필요하다. 따라서 “segementation” 함수, 즉 단어들을 구분지어서 statement와 question들을 구분시켜주는 학습시킬 함수를 사용한다. 이 함수를 segementer라 한다. 이 segementer을 사용하면 sequence를 memory에 쓸 수 있고 그 이후는 위에 나온 모델과 동일하게 사용하면된다. 그리고 이 segementer는 다른 component들과 같이 embedding model 형태이다.
여기서 $W_{seg}$는 vector이다. 이 vector의 역할은 embedding 된 값을 linear clasification 해주는 역할이다. 그리고 $c$는 input seqeunce로 vector 형태이다. 즉 각 단어들이 bag of words 형태로 들어온다. 따라서 이 함수의 결과값이 특정 margin $\gamma$보다 큰지 안큰지에 따라서 sequence가 하나의 segment인지 아닌지를 판단한다. 즉 아래와 같이 구분된다.
Result & Conclusion
실험결과에 대해서는 소개하지 않는다. 논문을 참고하길 바란다. 그리고 해당 모델은 하나의 Attention으로 볼 수 있는데, Hard attention으로 분류된다. 이후 다음 모델은 해당 모델보다 좀더 unsupervised한 성격의 모델로 Soft attention 성격의 모델이다. Memory를 사용하는 모델로 기존 RNN 혹은 LSTM 보다 성능이 좋다는 것을 확인할 수 있다.
오역 및 잘못된 내용이 있을 수 있습니다. 잘못된 부분 혹은 이해가 잘 안되는 부분은 댓글 혹은 메일로 말씀해주시면 감사하겠습니다!
Comments