
NLP를 위한 CNN (1): Understanding CNN for NLP
03 Aug 2018 | NLP
NLP에서 활용되는 Convolutional Network에 대해서 논문 하나씩 알아보도록 한다. 전체 List는 다음과 같다.
- Understanding CNN for NLP [현재글]
- Convolutional Neural Network for Sentence Classification, 2014
- A Convolutional Neural Network for Modelling Sentences, 2014
- A Sensitivity Analysis of Convolutional Neural Networks for Sentence Classification
- Character-level Convolutional Networks for Text Classification
첫 번째로는 논문이 아닌 NLP에서 사용되는 CNN에 대한 대략적인 이해를 위해 CNN의 NLP에서의 활용에 대한 설명을 할 것이다. 해당 내용은 제가 직접 구성한 내용이 아니라 블로그 글를 번역하고 나름 정리해서 쓴 글입니다. 의역이 포함되고 혹여나 오역이 있을 수 있어 원문과 비교하면서 읽으시는 것을 추천합니다!
Understanding Convolutional Neural Network for NLP
일반적으로 우리가 CNN를 생각하면 Computer Vision 분야를 대부분 떠올릴 것이다. 실제로 CNN은 Computer Vision 분야에서 많은 발전을 이뤘다. Image Classification, Image Detection, Semantic Segmentation 등 많은 분야에서도 CNN을 활용해서 성능 발전을 보여준 사례가 많다. 해당 분야에 대해서 좀 더 알고 싶다면 블로그 글을 참고하자.(Image Classification, Image Detection(1), (2) , Semantic Segmentation(1), (2))
좀 더 최근에는 CNN을 NLP문제에 활용하기 위한 많은 시도들을 했다. 사용한 NLP문제에서도 좋은 결과를 만들었다. 이 포스트에서는 CNN에 대한 내용을 간략히 소개하고 NLP에 CNN에 적용하는 방법에 대해 소개한다. CNN에 대한 직관적인 이해는 Computer Vision의 예를 들어 이해하는 것이 훨씬 쉬우므로 처음에는 Image를 예로들어 CNN에 대해서 알아보도록 한다.
Convolutional Neural Network (합성곱 신경망)
CNN은 window가 sliding 하며 Convolution 연산이 수행되는 과정이 포함된 네트워크이다. 아래의 그림은 Convolution하는 과정을 잘 보여준다.

CNN을 활용하는 예시를 생각해보자. 먼저 Image는 흑백이미지로 구성되며 각 pixel의 값은 0(black) 과 1(white) 값을 가진다고 하자. (일반적인 흑백 이미지는 0~255값을 가지는 grayscale이다.)
이제 이 Iamge는 Kernel, Filter, Feature detector라 불리는 window에 의해 합성곱이 이뤄질 것이다. 여기서는 3x3 크기의 필터를 사용했다고 생각하자. 이러한 Convolution 과정이 실제로 의미하는 바는 무었일까? 직관적인 이해를 위해서 다음의 두가지 의미로 해석할 수 있다.
-
픽셀값을 주변의 값들로 묶어 평균해서 Image를 흐리게 만든다.

-
주변의 pixel의 차이를 계산함으로써 edge를 찾는다.

좀 더 많은 예시는 GIMP manual에서 참고할 수 있다. 일반적인 CNN과정에 대해 더 알고 싶다면 포스트를 참고하자.
NLP문제에서의 CNN의 활용
Image Pixel대신 NLP문제를 해결할 때는 문장이나 전체 글을 matrix형태가 Input값이 된다. 이 matrix의 각 행은 하나의 token이 된다. token은 주로 단어가 된지만 경우에 따라 개별 문자가 하나의 token으로 활용하기도 한다. 즉 각 행은 단어 vector를 뜻한다. 대부분의 경우 이 단어 vector는 임베딩한 vector가 되는데 임베딩의 경우 word2vec 혹은 glove 기술을 통해 임베딩시킨 벡터이다. 경우에 따라 임베딩 시키지 않고 one-hot vector가 단어 vector가 될 수도 있다. 임베딩이든 one-hot이든 일단 벡터의 차원이 100차원이라 하고 token의 수, 즉 단어의 수를 10개라고 하면 이 matrix는 10x100 크기가 된다. 이 matrix가 우리의 “image”가 된다.
Vision 문제에서 필터는 image를 지역적으로 sliding한다. 그러나 NLP에서는 필터는 matrix의 모든 단어의 전체 행에 사용된다. 따라서 필터의 넓이는 보통 matrix의 넓이와 같다. 즉 단어벡터의 dimension과 같게 된다. 높이(or region size)는 달라지지만 보통의 경우 2~5개의 단어를 sliding한다. 위의 과정에 대해 아래 그림을 보며 좀더 정확히 이해해보자.
Computer Vision에서의 중요한 직관은 위치의 불변성과 지역적 결합이다. 그러나 NLP에 이러한 직관은 해당되지 않는다. pixel의 경우는 비슷한 위치에 있으면 거의 의미적으로도 비슷한 pixel이지만 단어의 경우에는 항상 이러한 경우가 성립하지는 않는다. 단어들은 몇 가지 방법으로 구성된다. 예를 들면 명사를 변형시킨 형용사와 같이 단어들이 어떤 규칙이 있다. 그러나 정확히 이러한 단어가 높은 단계에서 어떤 의미를 가지는지는 알기 어렵다.
이러한 모든 것들을 고려해볼때 CNN은 자연어 처리 분야에 적합하지 않아 보인다. Recurrent Neural Network가 훨씬 더 직관적으로 좋아보인다. RNN은 우리가 실제 언어를 사용하는 방법과 많이 비슷하다. 우리가 언어를 읽을 때도 왼쪽부터 오른쪽으로 순서대로 읽는 과정이 RNN과 비슷하다. 그러나 다행이도 이러한 내용이 CNN이 부적합하다는 것을 의미하지는 않는다. 다는 아니지만 몇몇의 모델은 유용하게 사용된다. Bag-of-Words 모델도 가정 자체가 지나치게 단순화해서 잘못된 가정이긴 하지만 그럼에도 불구하고 몇년동안 나름 좋은 결과를 만들어냈다.
CNN의 가장 큰 장점은 매우 빠르다는 것이다. 합성곱 자체가 컴퓨터 그래픽의 핵심적인 부분이고 GPU단계에서 잘 동작한다. n-gram모델같은 것들과 비교해서 CNN은 단어 표현에 효율적이다. 단어사전이 굉장히 큰 경우 3-gram만 해도 비용이 급격하게 증가한다. 심지어 구글조차 5-gram이상의 것들은 제공하지 않는다. Convolutional Filter는 전체 단어 사전 없이도 자동으로 좋은 단어표현을 학습시킨다. 그리고 이 필터의 크기가 5보다 크더라도 문제가 되지 않는다. 첫 번째 레이어에서 학습된 많은 필터가 n-gram과 유사하다고 생각한다. 그러나 조금 간결한 방법으로 표현한다.
CNN Hyperparameters
CNN이 어떻게 NLP 문제에 적용되는지 설명하기 전에 우선 Convolutional Neural Network를 만들 때 필요한 몇 가지 선택안에 대해서 살펴보자. 몇 가지 방안에 대해서 본다면 관련 분야에서 이해가 더 쉬워질 것이다.
Narrow vs Wide Convolution
위에서 Convolution을 설명할 때 자세한 내용은 생략했었다. 3x3 필터를 input의 중간에는 적용하는 것이 직관적이지만 가장 자리에는 3의 크기가 안나올 수 있다. 이런 경우는 어떻게 할까? 다들 알다시피 zero padding을 사용한다. 가장 자리에 추가로 모든 원소가 0을 갖도록 만들어 주는 것이다. 패딩을 함으로써 모든 matrix의 모든 요소에 대해 convolution을 수행할 수 있게 된다. 그리고 그 뿐만 아니라 input에 비해 좀 더 크거나 동일한 크기의 output을 갖게 된다. 즉 zero padding을 더한 것을 wide convolution 이라 부르고, 사용하지 않은 것을 narrow convolution 이라 부른다. 두 가지 방법을 1-dimension에 적용시킨 것을 그림으로 나타내면 다음과 같다.
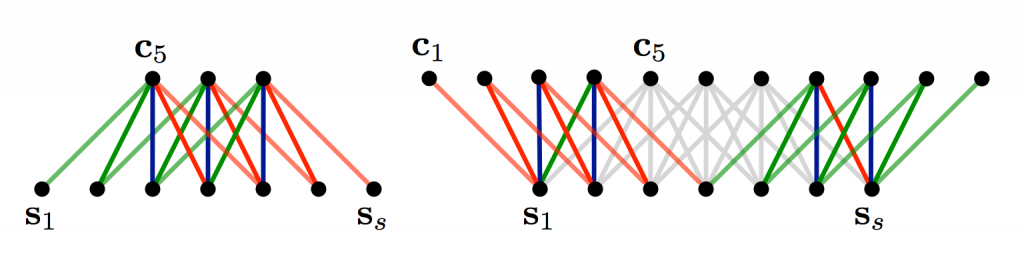
필터의 크기가 input 크기에 비해 상대적으로 큰 경우에 wide convolution을 필요로 한다. 위의 그림에서 narrow convolution(왼쪽)은 output size가 $(7-5)+1=3$이 되고, wide convolution(오른쪽)은 output size가 $(7+2*4-5)+1=11$이 된다. 더 일반적으로 공식으로 본다면 output 크기는 다음과 같다.
Stride Size
padding이외에 또 다른 hyperparameter는 stride size이다. 각 단게에서 필터가 얼만큼 움직여서 convolution을 수행할 지 결정하는 것이다. 위의 모든 그림은 stride가 1로 설정했을 때이고 이 경우에 convolution되는 부분이 겹쳐진다. 만약 stride를 크게 잡는다면 필터가 더 적게 사용될 것이고 output size도 작아질 것이다. 다음의 그림은 cs231의 stride 크기가 1과 2인 예제이다.
보통의 경우 stride는 1로 설정하지만 더 큰 stride사용한다면 Recursive Neural Network와 비슷한 효과를 만든다. 즉 tree구조가 되는 것이다.
Pooling Layers
CNN의 핵심은 pooling layer이다. 주로 convolution layer 다음에 적용된다. pooling layer는 input 값을 subsample하는 것과 같다. 보통 일반적으로는 max pooling을 사용한다. Pooling은 전체 matrix에 대해서 적용할 필요없이 window 크기를 정하고 해당 window에 대해서 pooling을 진행하면 된다. 아래 그림은 2x2 window로 max pooling을 하는 것을 보여준다.
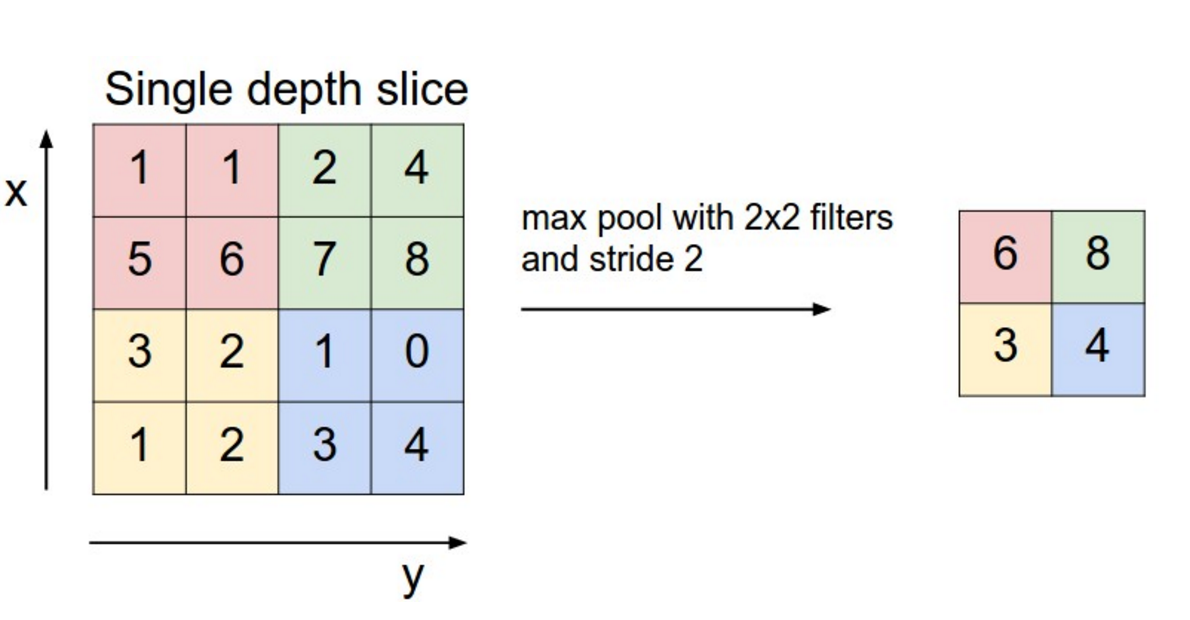
그렇다면 풀링은 왜하는 것일까? 두가지 정도의 이유가 있다. 첫 번째 이유는 보통 분류 문제에서 고정된 크기의 output을 만들기 위해서 사용한다. 예를 들면 1000개의 filter를 사용해서 풀링을 하면 input 값에 관계없이 1000-dimension의 output을 만들 수 있다. 이러한 특성은 NLP에서 매우 중요하자 우리가 input으로 길이가 각각 다른 문장을 넣을 수 있게 된 것이다. 언어의 특성상 문장의 길이는 대부분 항상 다른데 풀링을 사용함으로써 고정된 output dimension을 가질 수 있는 것이다.
그리고 두 번째로는 풀링은 크기(dimension)을 줄이지만, 중요한 정보는 모두 보존하기 때문이다. 각 필터에서 특정 특징들을 잘 추출한다. 예를들면 부정적인 내용인 “not amazing” 같은 것들이다. 만약 이 문구가 문장 어딘가에 등장했다면 필터를 적용하면 이 문구에 대한 수치가 높기 때문에 풀링 결과 그 수치가 나올 것이다. 따라서 풀링을 진행하면 각 필터에서 핵심적인 정보는모두 보존하는 것이다.
이미지 인식에서 풀링은 기본적인 움직임이나 회전에 대해 불변성을 제공한다. 한 부분에서 풀리을 할 때 output은 이미지를 적은 pixel로 회전하거나 이동시키더라도 거의 동일하다. 비슷한 지역에서 max값은 크게 변하지 않기 떄문이다.
Channels
마지막으로 필요한 것은 Channel에 대한 개념이다. Channel은 input이 어떤 것이냐에 따라 개념이 매우 달라진다. 예를들어 컬러 이미지를 input으로 한다면 Channel은 RGB 3개의 값을 각각 하나의 channel로 가질 것이다. NLP에서도 다양한 Channel을 생각할 수 있다. 예를 들면 word2vec으로 임베딩한 벡터들이 모인 matrix를 하나의 채널로 glove로 임베딩한 벡터들이 모인 matrix를 또 하나의 채널로 사용할 수도 있다. 또 다른 방법으로는 같은 문장에 대해 각 channel은 서로 다른 언어를 나타내는 방법도 있다.
NLP 적용하는 Convolutional Neural Network
이제 CNN의 자연어 처리 분야에서의 활용을 알아보자. 여러 연구 결과들에 대해서 요약해서 알아보도록 한다. 모든 흥미로운 연구들을 볼 수는 없지만, 최대한 유명한 연구들을 살펴 볼 것이다.
CNN이 가장 적합한 분야는 당연히 분류 문제일 것이다. 예를들면 감정 분석, 스팸 탐지, 주제 분류 등이 있을 것이다. Convolution 과 Pooling은 단어들의 순서에 관한 정보를 보존하지 않을 것이고, 따라서 순서가 중요한 PoS Tagging이나 Entitiy Extraction은 CNN을 통해 해결하기 어려울 것이다.(불가능은 아니다. 지역 특징을 input에 추가하면 가능하다.)
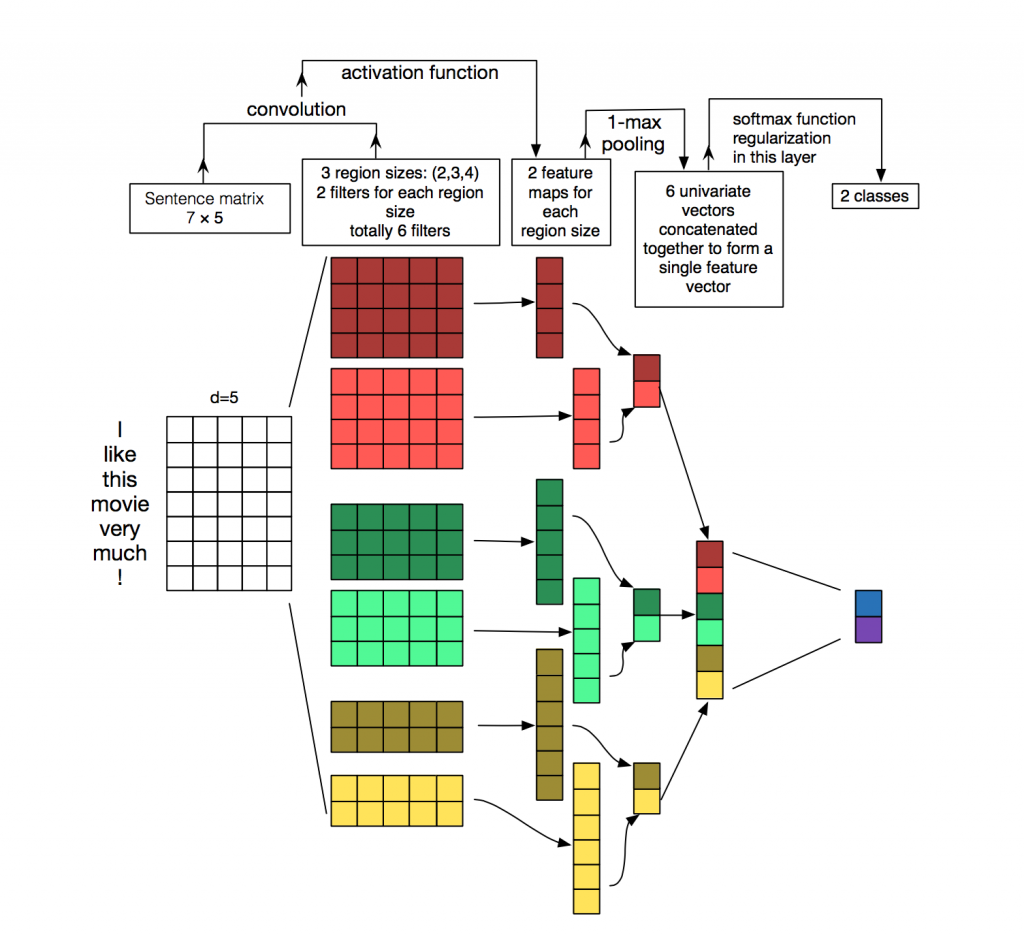
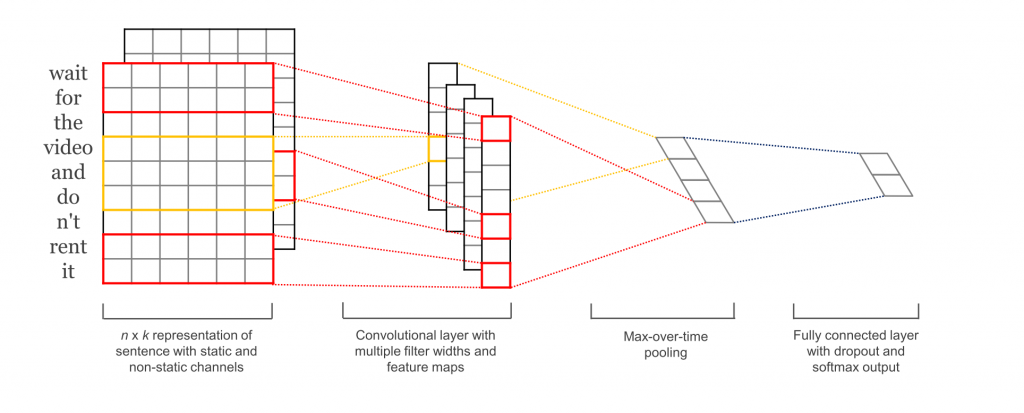
Convolutional Neural Networks for Sentence Classification(Kim Y,2014)은 CNN을 다양한 분류 dataset에 적용했다. 주로 감정 분석과 주제 분류문제이다. CNN architecture는 dataset마다 매우 좋은 성능을 보여줬다. 놀랍게도 논문에 사용된 network는 매우 간단하고 효과가 좋다. input값은 word2vec으로 임베딩된 단어들을 concat시킨 문장이다. 이후에 여러개의 filter로 convolution layer를 통과시킨 후 max-pooling layer를 통과시킨다. 마지막으로는 softmax함수를 사용해 분류를 했다. 그리고 이 논문을 보면 두개의 다른 채널을 사용해 실험했다. 하나의 채널은 정적인 단어 임베딩을 사용했고 나머지 하나는 동적인 단어 임베딩을 사용헀다. 이 네트워크는 기존의 CNN 네트워크 (Kalchbrenner, Wang)과 비슷한 구조를 사용했지만 몇가지 layer를 좀 더 추가했다. 추가한 layer는 “semantic clustering”을 하기 위한 layer이다. 아래는 이 논문의 architecture를 보여준다.
Effective use of Word Order for Text Categorization with Convolutional Neural Network(Johnson R & Zhang T, 2015)에서는 word2vec이나 Glove와 같은 걸로 임베딩시키지 않고 학습을 시킨다. one-hot vector를 바로 convolution하는 것이다. 저자는 space efficient bag of words like representation을 제안했다. 이는 학습해야 할 파라미터 수를 줄여준다.
그리고 Semi-supervised Convolutional Neural Networks for Text Categorization via Region Embedding(Johnson R & Zhang T, 2015)에서는 모델을 더욱 확장시켜서 text region의 context를 예측하는 CNN을 학습시키위해 unsupervised “region embedding”을 추가했다. 이러한 접근은 긴 글에서(ex.영화 리뷰) 더욱 잘 동작한다. 그러나 짧은 문장에서는(ex. tweets)에서는 좋은 성능을 보장하지는 않는다. 직관적으로 짧은 문장에서 미리 학습된 단어 임베딩을 사용하는 것이 긴 문장에서 사용하는 것 보다 더 많은 효율을 얻을 수 있다.
CNN 구조를 만드는 것은 위에서 소개된 것들처럼 많은 hyperparameter를 선택해야 한다. 선택해야 하는 것들은 다음과 같다.
- Input representation (word2vec, Glove, one-hot)
- 필터의 크기
- 풀링 전략(max, average)
- 활성화 함수(ReLU, tanh)
A Sensitivity Analysis of Convolutional Neural Netwroks for Sentence Classification(Zhang Y & Wallace B, 2015)에서는 CNN architecture에 사용되는 위와 같은 hyperparameter들 각각의 영향에 대해 실증적인 평가를 했다. text classification을 위한 CNN architecture를 직접 만들 계획을 하고 있다면 이 논문을 참고하면서 만드는 것을 추천한다. 몇 가지 나온 결과로는 max-pooling이 항상 average-pooling보다 좋은 성능을 보였고, 필터 크기는 중요하지만 어떤 작업이냐에 따라 다르다는 점이다. 그리고 정규화(regularization)는 NLP 문제에서는 크게 중요하지 않다는 것을 알 수 있다. 하지만 이런 논문 결과를 참고할 때 데이터의 구성이나 크기에 따라 많은 차이가 있을 수 있으므로 데이터가 어떤 구조인지 잘 살펴보고 참고해야 한다.
Relation Extraction: Perspective from Convolutional Neural Networks. Workshop on Vector Modeling for NLP(Nguyen T.H & Grishman R, 2015)에서는 관계 추출과 관계 분류 문제에 대해 연구했다. 저자는 우리가 관심있는 개체에 대한 상대적인 단어의 위치를 convolutional layer의 input값으로 사용했다. 이러한 모델은 각 개체의 위치가 주어졌다고 가정하고 각각의 input은 하나의 관계를 포함한다고 가정한다. Sun Y et al과 Zeng D도 비슷한 모델을 연구했다.
또 다른 NLP에서의 CNN활용한 것들 중 흥미로운 것은 Microsoft Research의 Modeling Interestingness with Deep Neural Network(Gao J et al, 2014)와 A Latent Semantic Model with COnvolutional-Pooling Structure for Information Retrieval(Sehn Y et al, 2014)이다. 이 논문들에서는 어떻게 정보 추출에서 사용될 수 있게 문장의 의미를 잘 표현할 수 있는 지를 소개한다. 주어진 예제는 사용자가 읽고있는 문서를 기반으로 잠재적으로 의미있는 문서를 추천하는 것이다. 문장 표현은 검색엔진의 log 데이터를 기반으로 학습되었다.
대부분의 CNN architecture들은 단어와 문장을 임베딩한다. 하지만 모든 논문이 이러한 부분의 학습에 집중하는 것은 아니다. Semantic Embeddings from Hashtags(Weston J & Adams K, 2014) 에서는 단어와 문장의 의미있는 임베딩을 만들어 내면서 Facebook의 해시태그를 예측하는 CNN architecture를 소개한다. 그들은 성공적으로 임베딩을 했으며 이 값으로 사용자 클릭 데이터를 기반으로한 문서 추천에 적용했다.
Character-Level CNNs
이때까지는 각 단어를 단위로 했다. 이제는 단어를 단위로 하는 것이 아니라 각 문자들을 바로 CNN에 사용하는 모델들을 알아보자.
Learning Character-level Representations for Part-of-Speech Tagging(Santos C & Zadrozny B, 2014)에서는 문자 단위의 임베딩을 학습했다. 그리고 학습한 문자 단위의 임베딩값을 미리 학습된 단어 임베딩을 결합해서 Speech tagging문제를 위한 CNN 구조에 사용했다.
Character-level Convolutional Networks for Text Classification(Zhang X & Zhao J, 2015)와 Text Understanding from Scratch(Zhang X & LeCun Y, 2015)에서는 어떠한 사전 학습된 임베딩값도 사용하지 않고 문자 단위로 바로 CNN에 학습시켰다. 여기서 주목할만한 점은 논문의 저자가 상대적으로 깊은 network를 사용했다는 점이다. 총 9층의 network를 사용해서 감정 분석과 Text Categorization 문제에 활용했다. 문자 단위를 바로 학습시킨 결과는 매우 큰 데이터셋(수 백만~)에서 잘 동작했다. 그러나 상대적으로 적은 데이터셋(수백~수천)에서는 좋은 결과를 보이지 못했다.
Character-Aware Neural Language Models(Kim Y et al, 2015)에서는 문자 단위의 CNN의 output값을 LSTM의 각 time step의 input으로 활용한 모델을 연구했다. 이 모델은 다양한 언어에 적용되었다.
여기까지가 CNN의 NLP문제에서의 활용에 대한 간략한 소개였다. 놀라운점은 위에 소개된 논문들이 불과 지난 2~3년밖에 안된 논문들이라는 점이다. 분명히 이전에서 NLP에서의 CNN의 활용이 있었지만 새로운 결과와 발표되는 최고수준의 시스템들은 계속해서 과속화되고 있다.
긴글 읽어주셔서 감사합니다. 오역 및 잘못된 내용이 있을 수 있습니다. 잘못된 부분 혹은 이해가 잘 안되는 부분은 댓글 혹은 메일로 말씀해주시면 감사하겠습니다!
NLP에서 활용되는 Convolutional Network에 대해서 논문 하나씩 알아보도록 한다. 전체 List는 다음과 같다.
- Understanding CNN for NLP [현재글]
- Convolutional Neural Network for Sentence Classification, 2014
- A Convolutional Neural Network for Modelling Sentences, 2014
- A Sensitivity Analysis of Convolutional Neural Networks for Sentence Classification
- Character-level Convolutional Networks for Text Classification
첫 번째로는 논문이 아닌 NLP에서 사용되는 CNN에 대한 대략적인 이해를 위해 CNN의 NLP에서의 활용에 대한 설명을 할 것이다. 해당 내용은 제가 직접 구성한 내용이 아니라 블로그 글를 번역하고 나름 정리해서 쓴 글입니다. 의역이 포함되고 혹여나 오역이 있을 수 있어 원문과 비교하면서 읽으시는 것을 추천합니다!
Understanding Convolutional Neural Network for NLP
일반적으로 우리가 CNN를 생각하면 Computer Vision 분야를 대부분 떠올릴 것이다. 실제로 CNN은 Computer Vision 분야에서 많은 발전을 이뤘다. Image Classification, Image Detection, Semantic Segmentation 등 많은 분야에서도 CNN을 활용해서 성능 발전을 보여준 사례가 많다. 해당 분야에 대해서 좀 더 알고 싶다면 블로그 글을 참고하자.(Image Classification, Image Detection(1), (2) , Semantic Segmentation(1), (2))
좀 더 최근에는 CNN을 NLP문제에 활용하기 위한 많은 시도들을 했다. 사용한 NLP문제에서도 좋은 결과를 만들었다. 이 포스트에서는 CNN에 대한 내용을 간략히 소개하고 NLP에 CNN에 적용하는 방법에 대해 소개한다. CNN에 대한 직관적인 이해는 Computer Vision의 예를 들어 이해하는 것이 훨씬 쉬우므로 처음에는 Image를 예로들어 CNN에 대해서 알아보도록 한다.
Convolutional Neural Network (합성곱 신경망)
CNN은 window가 sliding 하며 Convolution 연산이 수행되는 과정이 포함된 네트워크이다. 아래의 그림은 Convolution하는 과정을 잘 보여준다.
CNN을 활용하는 예시를 생각해보자. 먼저 Image는 흑백이미지로 구성되며 각 pixel의 값은 0(black) 과 1(white) 값을 가진다고 하자. (일반적인 흑백 이미지는 0~255값을 가지는 grayscale이다.)
이제 이 Iamge는 Kernel, Filter, Feature detector라 불리는 window에 의해 합성곱이 이뤄질 것이다. 여기서는 3x3 크기의 필터를 사용했다고 생각하자. 이러한 Convolution 과정이 실제로 의미하는 바는 무었일까? 직관적인 이해를 위해서 다음의 두가지 의미로 해석할 수 있다.
-
픽셀값을 주변의 값들로 묶어 평균해서 Image를 흐리게 만든다.
-
주변의 pixel의 차이를 계산함으로써 edge를 찾는다.
좀 더 많은 예시는 GIMP manual에서 참고할 수 있다. 일반적인 CNN과정에 대해 더 알고 싶다면 포스트를 참고하자.
NLP문제에서의 CNN의 활용
Image Pixel대신 NLP문제를 해결할 때는 문장이나 전체 글을 matrix형태가 Input값이 된다. 이 matrix의 각 행은 하나의 token이 된다. token은 주로 단어가 된지만 경우에 따라 개별 문자가 하나의 token으로 활용하기도 한다. 즉 각 행은 단어 vector를 뜻한다. 대부분의 경우 이 단어 vector는 임베딩한 vector가 되는데 임베딩의 경우 word2vec 혹은 glove 기술을 통해 임베딩시킨 벡터이다. 경우에 따라 임베딩 시키지 않고 one-hot vector가 단어 vector가 될 수도 있다. 임베딩이든 one-hot이든 일단 벡터의 차원이 100차원이라 하고 token의 수, 즉 단어의 수를 10개라고 하면 이 matrix는 10x100 크기가 된다. 이 matrix가 우리의 “image”가 된다.
Vision 문제에서 필터는 image를 지역적으로 sliding한다. 그러나 NLP에서는 필터는 matrix의 모든 단어의 전체 행에 사용된다. 따라서 필터의 넓이는 보통 matrix의 넓이와 같다. 즉 단어벡터의 dimension과 같게 된다. 높이(or region size)는 달라지지만 보통의 경우 2~5개의 단어를 sliding한다. 위의 과정에 대해 아래 그림을 보며 좀더 정확히 이해해보자.
Computer Vision에서의 중요한 직관은 위치의 불변성과 지역적 결합이다. 그러나 NLP에 이러한 직관은 해당되지 않는다. pixel의 경우는 비슷한 위치에 있으면 거의 의미적으로도 비슷한 pixel이지만 단어의 경우에는 항상 이러한 경우가 성립하지는 않는다. 단어들은 몇 가지 방법으로 구성된다. 예를 들면 명사를 변형시킨 형용사와 같이 단어들이 어떤 규칙이 있다. 그러나 정확히 이러한 단어가 높은 단계에서 어떤 의미를 가지는지는 알기 어렵다.
이러한 모든 것들을 고려해볼때 CNN은 자연어 처리 분야에 적합하지 않아 보인다. Recurrent Neural Network가 훨씬 더 직관적으로 좋아보인다. RNN은 우리가 실제 언어를 사용하는 방법과 많이 비슷하다. 우리가 언어를 읽을 때도 왼쪽부터 오른쪽으로 순서대로 읽는 과정이 RNN과 비슷하다. 그러나 다행이도 이러한 내용이 CNN이 부적합하다는 것을 의미하지는 않는다. 다는 아니지만 몇몇의 모델은 유용하게 사용된다. Bag-of-Words 모델도 가정 자체가 지나치게 단순화해서 잘못된 가정이긴 하지만 그럼에도 불구하고 몇년동안 나름 좋은 결과를 만들어냈다.
CNN의 가장 큰 장점은 매우 빠르다는 것이다. 합성곱 자체가 컴퓨터 그래픽의 핵심적인 부분이고 GPU단계에서 잘 동작한다. n-gram모델같은 것들과 비교해서 CNN은 단어 표현에 효율적이다. 단어사전이 굉장히 큰 경우 3-gram만 해도 비용이 급격하게 증가한다. 심지어 구글조차 5-gram이상의 것들은 제공하지 않는다. Convolutional Filter는 전체 단어 사전 없이도 자동으로 좋은 단어표현을 학습시킨다. 그리고 이 필터의 크기가 5보다 크더라도 문제가 되지 않는다. 첫 번째 레이어에서 학습된 많은 필터가 n-gram과 유사하다고 생각한다. 그러나 조금 간결한 방법으로 표현한다.
CNN Hyperparameters
CNN이 어떻게 NLP 문제에 적용되는지 설명하기 전에 우선 Convolutional Neural Network를 만들 때 필요한 몇 가지 선택안에 대해서 살펴보자. 몇 가지 방안에 대해서 본다면 관련 분야에서 이해가 더 쉬워질 것이다.
Narrow vs Wide Convolution
위에서 Convolution을 설명할 때 자세한 내용은 생략했었다. 3x3 필터를 input의 중간에는 적용하는 것이 직관적이지만 가장 자리에는 3의 크기가 안나올 수 있다. 이런 경우는 어떻게 할까? 다들 알다시피 zero padding을 사용한다. 가장 자리에 추가로 모든 원소가 0을 갖도록 만들어 주는 것이다. 패딩을 함으로써 모든 matrix의 모든 요소에 대해 convolution을 수행할 수 있게 된다. 그리고 그 뿐만 아니라 input에 비해 좀 더 크거나 동일한 크기의 output을 갖게 된다. 즉 zero padding을 더한 것을 wide convolution 이라 부르고, 사용하지 않은 것을 narrow convolution 이라 부른다. 두 가지 방법을 1-dimension에 적용시킨 것을 그림으로 나타내면 다음과 같다.
필터의 크기가 input 크기에 비해 상대적으로 큰 경우에 wide convolution을 필요로 한다. 위의 그림에서 narrow convolution(왼쪽)은 output size가 $(7-5)+1=3$이 되고, wide convolution(오른쪽)은 output size가 $(7+2*4-5)+1=11$이 된다. 더 일반적으로 공식으로 본다면 output 크기는 다음과 같다.
Stride Size
padding이외에 또 다른 hyperparameter는 stride size이다. 각 단게에서 필터가 얼만큼 움직여서 convolution을 수행할 지 결정하는 것이다. 위의 모든 그림은 stride가 1로 설정했을 때이고 이 경우에 convolution되는 부분이 겹쳐진다. 만약 stride를 크게 잡는다면 필터가 더 적게 사용될 것이고 output size도 작아질 것이다. 다음의 그림은 cs231의 stride 크기가 1과 2인 예제이다.
보통의 경우 stride는 1로 설정하지만 더 큰 stride사용한다면 Recursive Neural Network와 비슷한 효과를 만든다. 즉 tree구조가 되는 것이다.
Pooling Layers
CNN의 핵심은 pooling layer이다. 주로 convolution layer 다음에 적용된다. pooling layer는 input 값을 subsample하는 것과 같다. 보통 일반적으로는 max pooling을 사용한다. Pooling은 전체 matrix에 대해서 적용할 필요없이 window 크기를 정하고 해당 window에 대해서 pooling을 진행하면 된다. 아래 그림은 2x2 window로 max pooling을 하는 것을 보여준다.
그렇다면 풀링은 왜하는 것일까? 두가지 정도의 이유가 있다. 첫 번째 이유는 보통 분류 문제에서 고정된 크기의 output을 만들기 위해서 사용한다. 예를 들면 1000개의 filter를 사용해서 풀링을 하면 input 값에 관계없이 1000-dimension의 output을 만들 수 있다. 이러한 특성은 NLP에서 매우 중요하자 우리가 input으로 길이가 각각 다른 문장을 넣을 수 있게 된 것이다. 언어의 특성상 문장의 길이는 대부분 항상 다른데 풀링을 사용함으로써 고정된 output dimension을 가질 수 있는 것이다.
그리고 두 번째로는 풀링은 크기(dimension)을 줄이지만, 중요한 정보는 모두 보존하기 때문이다. 각 필터에서 특정 특징들을 잘 추출한다. 예를들면 부정적인 내용인 “not amazing” 같은 것들이다. 만약 이 문구가 문장 어딘가에 등장했다면 필터를 적용하면 이 문구에 대한 수치가 높기 때문에 풀링 결과 그 수치가 나올 것이다. 따라서 풀링을 진행하면 각 필터에서 핵심적인 정보는모두 보존하는 것이다.
이미지 인식에서 풀링은 기본적인 움직임이나 회전에 대해 불변성을 제공한다. 한 부분에서 풀리을 할 때 output은 이미지를 적은 pixel로 회전하거나 이동시키더라도 거의 동일하다. 비슷한 지역에서 max값은 크게 변하지 않기 떄문이다.
Channels
마지막으로 필요한 것은 Channel에 대한 개념이다. Channel은 input이 어떤 것이냐에 따라 개념이 매우 달라진다. 예를들어 컬러 이미지를 input으로 한다면 Channel은 RGB 3개의 값을 각각 하나의 channel로 가질 것이다. NLP에서도 다양한 Channel을 생각할 수 있다. 예를 들면 word2vec으로 임베딩한 벡터들이 모인 matrix를 하나의 채널로 glove로 임베딩한 벡터들이 모인 matrix를 또 하나의 채널로 사용할 수도 있다. 또 다른 방법으로는 같은 문장에 대해 각 channel은 서로 다른 언어를 나타내는 방법도 있다.
NLP 적용하는 Convolutional Neural Network
이제 CNN의 자연어 처리 분야에서의 활용을 알아보자. 여러 연구 결과들에 대해서 요약해서 알아보도록 한다. 모든 흥미로운 연구들을 볼 수는 없지만, 최대한 유명한 연구들을 살펴 볼 것이다.
CNN이 가장 적합한 분야는 당연히 분류 문제일 것이다. 예를들면 감정 분석, 스팸 탐지, 주제 분류 등이 있을 것이다. Convolution 과 Pooling은 단어들의 순서에 관한 정보를 보존하지 않을 것이고, 따라서 순서가 중요한 PoS Tagging이나 Entitiy Extraction은 CNN을 통해 해결하기 어려울 것이다.(불가능은 아니다. 지역 특징을 input에 추가하면 가능하다.)
Convolutional Neural Networks for Sentence Classification(Kim Y,2014)은 CNN을 다양한 분류 dataset에 적용했다. 주로 감정 분석과 주제 분류문제이다. CNN architecture는 dataset마다 매우 좋은 성능을 보여줬다. 놀랍게도 논문에 사용된 network는 매우 간단하고 효과가 좋다. input값은 word2vec으로 임베딩된 단어들을 concat시킨 문장이다. 이후에 여러개의 filter로 convolution layer를 통과시킨 후 max-pooling layer를 통과시킨다. 마지막으로는 softmax함수를 사용해 분류를 했다. 그리고 이 논문을 보면 두개의 다른 채널을 사용해 실험했다. 하나의 채널은 정적인 단어 임베딩을 사용했고 나머지 하나는 동적인 단어 임베딩을 사용헀다. 이 네트워크는 기존의 CNN 네트워크 (Kalchbrenner, Wang)과 비슷한 구조를 사용했지만 몇가지 layer를 좀 더 추가했다. 추가한 layer는 “semantic clustering”을 하기 위한 layer이다. 아래는 이 논문의 architecture를 보여준다.
Effective use of Word Order for Text Categorization with Convolutional Neural Network(Johnson R & Zhang T, 2015)에서는 word2vec이나 Glove와 같은 걸로 임베딩시키지 않고 학습을 시킨다. one-hot vector를 바로 convolution하는 것이다. 저자는 space efficient bag of words like representation을 제안했다. 이는 학습해야 할 파라미터 수를 줄여준다.
그리고 Semi-supervised Convolutional Neural Networks for Text Categorization via Region Embedding(Johnson R & Zhang T, 2015)에서는 모델을 더욱 확장시켜서 text region의 context를 예측하는 CNN을 학습시키위해 unsupervised “region embedding”을 추가했다. 이러한 접근은 긴 글에서(ex.영화 리뷰) 더욱 잘 동작한다. 그러나 짧은 문장에서는(ex. tweets)에서는 좋은 성능을 보장하지는 않는다. 직관적으로 짧은 문장에서 미리 학습된 단어 임베딩을 사용하는 것이 긴 문장에서 사용하는 것 보다 더 많은 효율을 얻을 수 있다.
CNN 구조를 만드는 것은 위에서 소개된 것들처럼 많은 hyperparameter를 선택해야 한다. 선택해야 하는 것들은 다음과 같다.
- Input representation (word2vec, Glove, one-hot)
- 필터의 크기
- 풀링 전략(max, average)
- 활성화 함수(ReLU, tanh)
A Sensitivity Analysis of Convolutional Neural Netwroks for Sentence Classification(Zhang Y & Wallace B, 2015)에서는 CNN architecture에 사용되는 위와 같은 hyperparameter들 각각의 영향에 대해 실증적인 평가를 했다. text classification을 위한 CNN architecture를 직접 만들 계획을 하고 있다면 이 논문을 참고하면서 만드는 것을 추천한다. 몇 가지 나온 결과로는 max-pooling이 항상 average-pooling보다 좋은 성능을 보였고, 필터 크기는 중요하지만 어떤 작업이냐에 따라 다르다는 점이다. 그리고 정규화(regularization)는 NLP 문제에서는 크게 중요하지 않다는 것을 알 수 있다. 하지만 이런 논문 결과를 참고할 때 데이터의 구성이나 크기에 따라 많은 차이가 있을 수 있으므로 데이터가 어떤 구조인지 잘 살펴보고 참고해야 한다.
Relation Extraction: Perspective from Convolutional Neural Networks. Workshop on Vector Modeling for NLP(Nguyen T.H & Grishman R, 2015)에서는 관계 추출과 관계 분류 문제에 대해 연구했다. 저자는 우리가 관심있는 개체에 대한 상대적인 단어의 위치를 convolutional layer의 input값으로 사용했다. 이러한 모델은 각 개체의 위치가 주어졌다고 가정하고 각각의 input은 하나의 관계를 포함한다고 가정한다. Sun Y et al과 Zeng D도 비슷한 모델을 연구했다.
또 다른 NLP에서의 CNN활용한 것들 중 흥미로운 것은 Microsoft Research의 Modeling Interestingness with Deep Neural Network(Gao J et al, 2014)와 A Latent Semantic Model with COnvolutional-Pooling Structure for Information Retrieval(Sehn Y et al, 2014)이다. 이 논문들에서는 어떻게 정보 추출에서 사용될 수 있게 문장의 의미를 잘 표현할 수 있는 지를 소개한다. 주어진 예제는 사용자가 읽고있는 문서를 기반으로 잠재적으로 의미있는 문서를 추천하는 것이다. 문장 표현은 검색엔진의 log 데이터를 기반으로 학습되었다.
대부분의 CNN architecture들은 단어와 문장을 임베딩한다. 하지만 모든 논문이 이러한 부분의 학습에 집중하는 것은 아니다. Semantic Embeddings from Hashtags(Weston J & Adams K, 2014) 에서는 단어와 문장의 의미있는 임베딩을 만들어 내면서 Facebook의 해시태그를 예측하는 CNN architecture를 소개한다. 그들은 성공적으로 임베딩을 했으며 이 값으로 사용자 클릭 데이터를 기반으로한 문서 추천에 적용했다.
Character-Level CNNs
이때까지는 각 단어를 단위로 했다. 이제는 단어를 단위로 하는 것이 아니라 각 문자들을 바로 CNN에 사용하는 모델들을 알아보자.
Learning Character-level Representations for Part-of-Speech Tagging(Santos C & Zadrozny B, 2014)에서는 문자 단위의 임베딩을 학습했다. 그리고 학습한 문자 단위의 임베딩값을 미리 학습된 단어 임베딩을 결합해서 Speech tagging문제를 위한 CNN 구조에 사용했다.
Character-level Convolutional Networks for Text Classification(Zhang X & Zhao J, 2015)와 Text Understanding from Scratch(Zhang X & LeCun Y, 2015)에서는 어떠한 사전 학습된 임베딩값도 사용하지 않고 문자 단위로 바로 CNN에 학습시켰다. 여기서 주목할만한 점은 논문의 저자가 상대적으로 깊은 network를 사용했다는 점이다. 총 9층의 network를 사용해서 감정 분석과 Text Categorization 문제에 활용했다. 문자 단위를 바로 학습시킨 결과는 매우 큰 데이터셋(수 백만~)에서 잘 동작했다. 그러나 상대적으로 적은 데이터셋(수백~수천)에서는 좋은 결과를 보이지 못했다.
Character-Aware Neural Language Models(Kim Y et al, 2015)에서는 문자 단위의 CNN의 output값을 LSTM의 각 time step의 input으로 활용한 모델을 연구했다. 이 모델은 다양한 언어에 적용되었다.
여기까지가 CNN의 NLP문제에서의 활용에 대한 간략한 소개였다. 놀라운점은 위에 소개된 논문들이 불과 지난 2~3년밖에 안된 논문들이라는 점이다. 분명히 이전에서 NLP에서의 CNN의 활용이 있었지만 새로운 결과와 발표되는 최고수준의 시스템들은 계속해서 과속화되고 있다.
긴글 읽어주셔서 감사합니다. 오역 및 잘못된 내용이 있을 수 있습니다. 잘못된 부분 혹은 이해가 잘 안되는 부분은 댓글 혹은 메일로 말씀해주시면 감사하겠습니다!
Comments